How OAuth 2.0 and OpenID Connect works
OAuth which stands for Open Authorization is the de facto industry standard for online authorization. By using OAuth you can grant a 3rd party application limited access to an HTTP service either on behalf of a user or directly.
3rd party applications in this context can be browser-based applications like classic dynamic server-side web applications, single-page applications (SPA), mobile apps, connected devices, … all of them must be capable to use the HTTP protocol.
In OAuth terminology the 3rd party application is named as client and the HTTP service is the resource server or API.
If the access to the HTTP service is granted on behalf of a user, this user is the resource owner in OAuth terminology.
- Introduction
- OAuth 2.0 authorization code flow for confidential clients
- OAuth 2.0 terminology
- 1. Step authorization code flow
- 2. Step authorization code flow
- 3. Step authorization code flow
- 4. Step authorization code flow
- 5. Step authorization code flow
- OAuth Front Channel vs Back Channel
- Tokens used in OAuth 2.0 and OpenID Connect
- PKCE
- Device Authorization Flow
- History of OAuth
- User consent settings in Microsoft 365
- Public 3rd party applications requesting consent in Azure AD.
- Links
Introduction
For example you want that users can login to your website by using their google accounts. In this case your website is the client, Google’s Url and HTTP service behind https://accounts.google.com is the resource server (API), and the user who logs into your website by using his google account is the resource owner because it is his own user profile on the resource server to which he grants access for your website.
So if you login to a 3rd party web application by using your Google, Microsoft, Facebook, Twitter … account, you still using OAuth 2.0 and OpenID Connect.
In case of the example above by using your social media account to login into another web application, you only use a small part of the capabilities of OAuth 2.0 and OpenID Connect.
A small part because the web application you want to login in, only requests your profile information like email address or name from a different HTTP service.
With OAuth you can authorizing 3rd party applications for almost everything to do or request at a different HTTP service on behalf of a user or directly.
Microsoft 365 apps like Exchange Online, SharePoint Online, Teams, Dynamics 365, OneDrive … also relies on OAuth 2.0 and OpenID Connect.
Here for example when you want to login to your Exchange Online mailbox by using Outlook on the web and entering the Url https://outlook.office.com into your browser, you will first get redirected to the authorization server from Microsoft under the following Url https://login.microsoftonline.com/common/oauth2/authorize?client_id=xxxx&redirect_uri=outlook.office.com&response_type=code+id_token&scope=openid (Url query parameter shortened), to authenticate yourself, provided the login was successful, the Outlook on the web app will get an access token and id token to access your mailbox on the Exchange Online Server and on behalf of you.
What each parameter and value in the Url above means we will see and deal with further below in detail.
The authorization server is some kind of Identity Provider (IdP) where the user is redirected to from the 3rd party application, to provide his login credentials to authenticate himself against the authorization server. In response after the user authenticated successfully, the authorization server issued an access token to access the actual HTTP service resource server (API) on behalf of the user by the 3rd party application.
In case of by default not trusted applications for the authorization server, the user first have consent to allow the access by the not trusted application, before the authorization server issued in response these access tokens.
Btw. the authorization server and resource server can be on the same server and system or on completely different systems.
OAuth 2.0 is an authorization framework and is used to delegate authorization between servers. It has nothing to do with authentication.
Once a user authenticates against an authorization server (like Google, Microsoft Facebook , Twitter, …), the authorization server delegates the authorization for the HTTP service resource server (API) in form of an access token to the 3rd-party application the user wants to access.
OAuth does not provide any information about the user itself and how they authenticated against the authorization server. OAuth was designed for permissions so called scopes defined in the issued access tokens, they define what an 3rd party application can do with and have access to. OAuth is not interesting in who the user actually is.
Therefore the OpenID Connect extension adds a small identity layer on top of the OAuth framework.
OpenID Connect (OIDC) enables the authorization server to not only issue access tokens but also ID tokens to the 3rd party application (client), in this case the authorization server is also an OpenID Connect-Provider (OP) and Identity Provider (IdP).
So OpenID Connect not handling the authentication process at the authorization server itself, it only adds an ID token in response to the request from the client.
Real so called Identity Provider (IdP) are capable of authenticating users and issuing access and ID tokens with claims about the user. So the on-premises Active Directory itself in this term is actually not a real IdP in contrast to the Azure AD, as it is not capable of issuing tokens to clients, only Kerberos tickets.
Therefore to provide an IdP with Active Directory you need to add the AD FS server role to your Active Directory environment, which forwards the actual process of authentication to the Active Directory and domain controllers, and in case of an successful authentication, AD FS responses with an access token and ID token to the client request. Actually it also issues refresh tokens in addition to the access tokens like other authorization servers, we will see this in detail further below.
AD FS OpenID Connect/OAuth Concepts
https://docs.microsoft.com/en-us/windows-server/identity/ad-fs/development/ad-fs-openid-connect-oauth-concepts
ID tokens provides information (named claims -> parameter <-> value) about the user itself and some meta and security data like:
- User ID -> Who is the user that got authenticated
- iss (issuer) -> Where was he authenticated
- auth_time -> When was he authenticated
- amr (authentication methods reference) -> How was he authenticated -> by using a password or a second factor or other types like biometric authentication
- nonce -> (number used once) used to protect against an injection attack
- c_hash -> a hash of the authorization code itself, which you can use to verify that that code wasn’t swapped out in that response.
- and more …
which can then be used by the 3rd party application to manage access and permissions.
So OpenID Connect provides user identity and authentication on top of the OAuth framework.
Clients can verify the identity of the user and getting profile information from based on the authentication performed by an authorization server.As OpenID Connect is also an open standard it works with multiple IdPs and uses IETF’s JSON Web Signature standard.
One of the great benefits you will get with OAuth 2.0 and OpenID Connect, is that you can set the focus on developing the main functionality of your application and don’t have to worry about how to implement the authentication for the users.
This part is then handled from a separate dedicated service, the authorization server with the OpenID Connect extension. You can use here an existing provider like Microsoft, Facebook, Google, Twitter, …. or you can also developing your own authorization server.
Originally Facebook, Google, Microsoft, Yahoo, Twitter and others introduced social login by using OAuth 2.0 under the hood.
In OAuth there are a set of different process steps named Grant Type or Flow, a client have to perform in order to get access to the HTTP service (resource server or API).
The OAuth authorization framework provides a set of different grant types, the four basic grant types by most providers supported are:
- Authorization Code Grant -> recommended by using PKCE (Proof Key for Code Exchange) in addition.
The client first requests an authorization code from the authorization server by using the front channel (address bar) of the browser and then secondly exchanges this authorization code (including the applications client ID, client secret and PKCE secret) with the authorization server by using a back channel (HTTP post) directly between the app (client) on the server and the authorization server in order to get an access token for the resource server (API). - Password Grant
The 3rd party application requested the user’s username and password to request an access token from the authorization server. Actually this was the reason why OAuth was developed to prevent this scenario. This Grant type only should be used for apps they natively are trusted by the resource server (API) and belongs to them and therefore trusted by default. - Implicit Grant
In contrast to the authorization code grant, the client requests directly an access token by using the front channel. So the access token is delivered in response to the request by using a redirect uri (address bar) or a form post. Redirect uri is now deprecated due to security leaks. - Client Credentials Grant
One of the simplest grant types in OAuth. There is no browser and user involved and therefore no redirects. In this case the application uses his own credentials to exchange them for an access token. This type is used to grant an application access to its own resources.
There are also further grant types providers may support like the
- Device Authorization Flow
which I will also explain here further below.
In the figure below you will see how OAuth 2.0 basically works by using the most common used Authorization Code flow.
The figure I derived from Nate Barbettini and his great introduction in OAuth 2.0 and OpenID Connect which you can watch in the following youtube video.
OAuth 2.0 and OpenID Connect (in plain English)
https://www.youtube.com/watch?v=996OiexHze0
If you want to dig deeper in details how OAuth 2.0 exactly works, I can also recommend to watch the following great course at udemy with Aaron Parecki. He explained fantastic all you need to know about OAuth 2.0, further he also writes the book OAuth 2.0 Simplified which also includes the staff from the course plus addition information.
The Nuts and Bolts of OAuth 2.0
https://www.udemy.com/course/oauth-2-simplified/
OAuth 2.0 Simplified
https://oauth2simplified.com/
OAuth 2.0 Simplified is a guide to building an OAuth 2.0 server. Through high-level overviews, step-by-step instructions, and real-world examples, you will learn how to take advantage of the OAuth 2.0 framework while building a secure API.
Further a great source and detailed description about how the OAuth 2.0 Authorization Framework works, you will find in the following request for comments.
RFC 6749
The OAuth 2.0 Authorization Framework
https://datatracker.ietf.org/doc/html/rfc6749
OAuth 2.0 authorization code flow for confidential clients
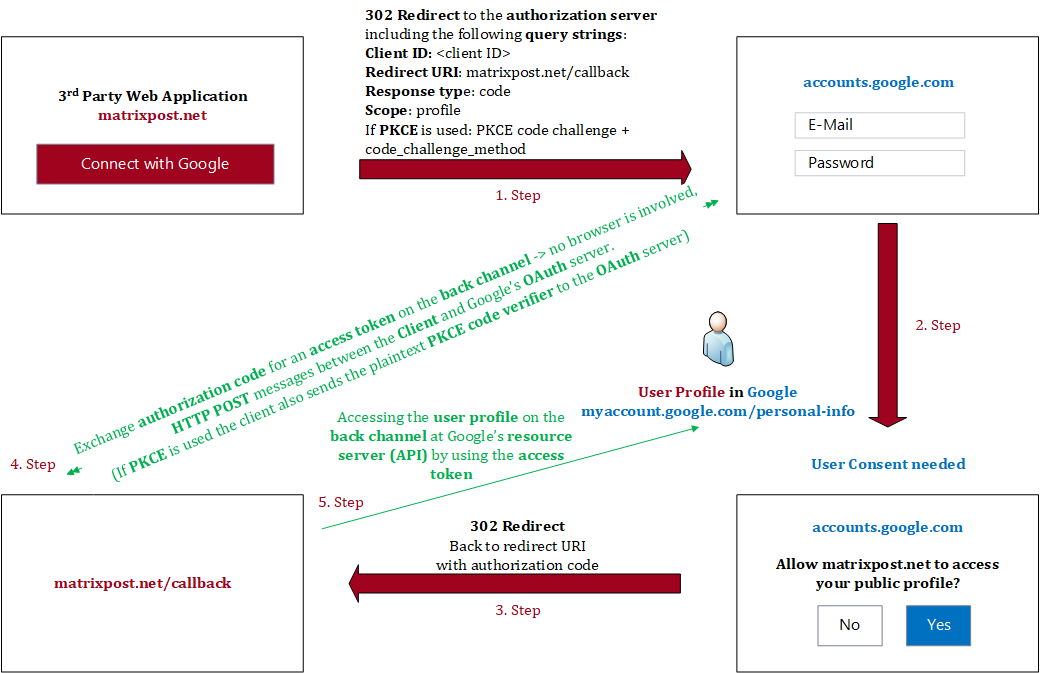
The 5 steps in the figure above are colored in red and green. The red ones (step 1 to 3) are processed in the front channel and the green ones (step 4 + 5) in the back channel.
I will go in detail about both channels further below, in advance the front channel is less secure by transmitting data through the browsers address bar and the back channel is a highly secure channel by using secure HTTP Post messages directly between the app and the authorization server, no browser is involved in this communication.
Before we will go through the separate steps from the figure above in detail, it’s important to understand the following terminology of OAuth 2.0.
OAuth 2.0 terminology
- Resource owner -> User who owns the requested data from the resource server or API like the Google’s user account profile.
- Client -> Application who wants to access the HTTP service (resource server or API)
- Authorization server -> Also a HTTP service who will provide authentication for the resource server. Some kind of Identity Provider (IdP).
- Resource server -> separate from the authorization server, an API to access the actual HTTP service which provides the data and function like accounts.google.com for the users profile data. Sometimes the authorization server and the resource server are the same system but not have to be necessarily.
- Access token -> permission proof to make API requests to the HTTP service so called delegated authorization
- Back channel -> highly secure channel – direct communication between the web application (Client) and the authorization server and resource server and no browser is involved. The back channel is an HTTP call (HTTP POST) directly from the client application on the server to the authorization server to exchange the authorization code for access tokens. Also the access from the client to the resource server (API) will go through the back channel.
- Front channel -> less secure channel – communication by using the browsers address bar between the client application and authorization server.
- Credentials -> Client ID, Client Secret, (Client URI, Client Redirect URI) -> provide the required information about the caller making a request to a API. -> You will get the Client ID and Client Secret during registering your app at the authorization server (Google APIs & Services, Azure Portal App registrations, …).
To describe these separate steps, I will using the ASP.NET web app from my following post.
Using Google’s OAuth 2.0 API for an ASP.NET Core Web App
https://blog.matrixpost.net/using-googles-oauth-2-0-api-for-an-asp-net-core-web-app/
1. Step authorization code flow
After clicking the button Connect with Google at my web application, I will get redirected on the front channel to the authorization server from Google where I need to provide my username and password from my google account to authenticate myself.


URL:
https://accounts.google.com/o/oauth2/v2/auth/identifier?response_type=code&client_id=64244310775-njimip3pn8gvhbvqto76sfom8bn0sv7t.apps.googleusercontent.com&redirect_uri=https%3A%2F%2Flocalhost%3A44377%2Fsignin-google&scope=openid%20profile%20email&state=CfDJ8Gau9MjUZ-LxfWvMBiyDzROeA&flowName=GeneralOAuthFlow
URL query string parameter:
starting with:
response_type=code -> That tells the server that you’re doing the authorization code flow. This parameter is used in the front channel against the authorization endpoint. In contrast the back channel uses the parameter grant_type (4. Step here) which is used against the token endpoint and defines the grant used for.
client_id -> tells the OAuth server which app is making this request. The app is registered at the authorization server by this client id, so it trusts the application.
redirect_uri -> it has to match one of the redirect URLs you added when you registered the app. I used here localhost/signin-google for testing purpose.
scope -> permissions to request based on the API that you’re trying to access. For example email. The scope openid tells the authorization server that you also want an ID token in addition to the access token.
state -> The state parameter was originally used for CSRF protection, but PKCE provides that protection as well, so you can use it for storing application specific state now, such as which page to redirect the user to after they log in, like cart or checkout. If the server doesn’t support PKCE, then you will need to make this a random value.
My application don’t uses PKCE as you can see in the request URL above, where the code_challenge and code_challenge_method parameter are missing, but Google also supports PKCE as you can read in the following article from Google.https://developers.google.com/identity/protocols/oauth2/native-app
As you can see, the redirect URI included the client id of my application, the response type code, the scopes (profile, openid and email) and a state. Parameter for PKCE like code_challenge and code_verifier as mentioned are missing, so the authorization code flow doesn’t uses PKCE in my case.
More about PKCE you will find further below.
2. Step authorization code flow
Here I will get prompted from the Google Authorization Server to login with my Google account. As you can see above in the figure, Google tells me that if I continue, it will share my name, email address, language preferences and profile picture with my web application. This step is the User Consent.
I will consent that the application can access my profile data at Google by using the later in step 5. issued access token from the authorization server.
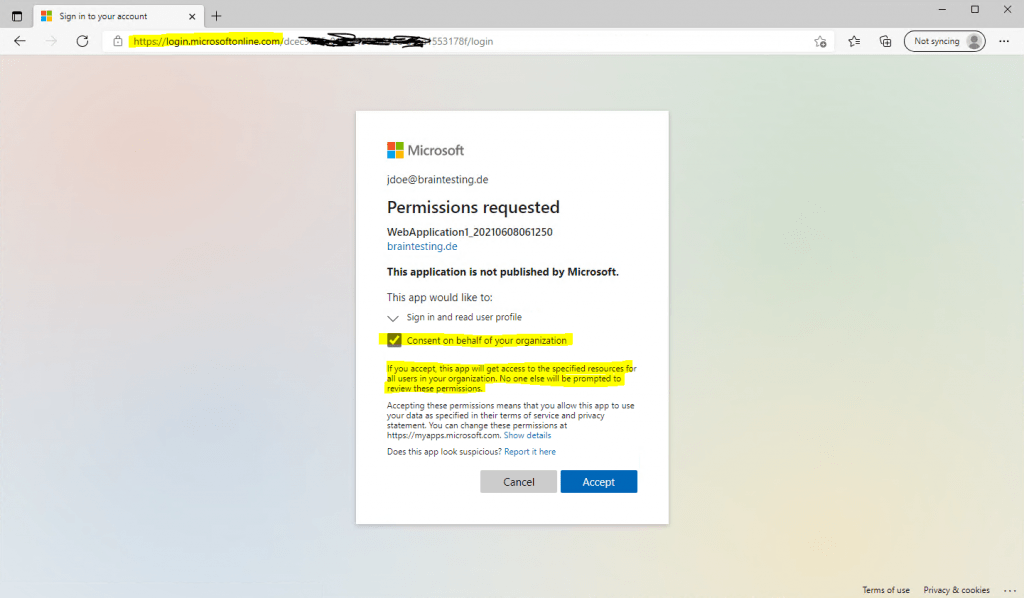
Using Azure AD as Authorization Server will prompt with the following consent screen.
3. Step authorization code flow
After accepting and approving the permission request from the web application to access my profile, I will get redirected back on the front channel to my web application by using the configured redirect URI, which we configured at registering the app to the API Provider.
Further the one time use authorization code is included in the redirect URI. If it will run into an error, the redirect URI will include an error code instead of the authorization code.
4. Step authorization code flow
The authorization code which is included in the redirect URI from step 3, is used by the web application to request an access token by using a back channel to the authorization server in the next step.
The back channel is as mentioned a HTTP POST request directly from the web application (Client) to the authorization server and separate token endpoint URI.
POST https://authorization-server.com/token
The parameters in this request will be:
grant_type=authorization_code&. This tells the server that you’re doing the authorization code grant.
code=AUTH_CODE_HERE&
redirect_uri=REDIRCT_URI&
code_verifier=VERIFIER_STRING&. Only used with PKCE.
client_id=CLIENT_ID&
client_secret=CLIENT_SECRET.
Different servers may expect this either in the post body or as in basic OAuth header.
In reply if everything works fine, the authorization server will post back with an access token, the expiration time of the token and possibly also a refresh token. Now my app is done with the OAuth flow and it can use that access token to make API requests (5. Step here). If you got back a refresh token, then when the current access token expires, you can use the refresh token to get a new access token without going through that whole flow again. Using the refresh token is a lot like using the authorization code.
By using the refresh token to request an access token, the grant_type parameter in the HTTP POST request above from the back channel will be refresh_token instead authorization_code. Further it needs to include the parameter refresh_token=refresh_token&client_id=CLIENT_ID&client_secret=CLIENT_SECRET.
The authorization code is transmitted through the front channel, but this is not critical. If someone intercepts this code, it cannot use it as the exchange with the Auth Server (Google) only occurs and works on the back channel.
The back channel use this authorization code together with an client secret which cannot be intercepted through the browser. The client secret is stored on the server from the client application.
How to get resp. create this client secret along with a client id, you will see in my following post about how to configure an ASP.NET Core Web App using Google’s OAuth 2.0 API.
5. Step authorization code flow
In step 4 the web application requests the access token and ID token by using the authorization code together with a client secret on the secure back channel. Now my web application (Client) can access the resource server (Google API), by using this access token, to read my profile data.
The information (claims) from the ID token can be used by the web application to manage access and permissions for it.
OAuth Front Channel vs Back Channel
The OAuth flow uses different ways to transmit data between all parties involved in that flow. The front channel is in a nutshell the address bar from the user’s browser and HTTP redirect messages from and to the client (web application) and authorization server.
The browser is needed for all flows a client (application) should access the resource server (API) on behalf of a user. The reason for is that in this case the user have to provide its credentials directly to the authorization server and also needs to be able to consent to the authorization server, that the client (application) used by it is allowed to access the resource server (API) on behalf of the user.
And only when the user is consent to, the authorization server will send in response an authorization code, which then can be used by the client (application) to request an access token for the resource server (API).
The first HTTP message what is transmitted by using the front channel, is an HTTP redirect message the client (application) initiated and responses to the user, to route the user’s browser to the authorization server.
In this first HTTP redirect message, the client appends its client ID, scope, redirect uri, response type like code for the authorization code flow and state to the redirect URI.
All these appended parameter (query strings) will be transmitted with the second HTTP message by using a GET method request from the user’s browser and therefore also the front channel to the authorization server. Therefore these parameters will be transmitted unencrypted and can be seen by anyone in the address bar, browser history, cache and also in the log files from the server.
But this is not really critical as all of these parameters like the client ID, scope, response type, … aren’t confidential, all of them can be seen by anyone.
The authorization server will then prompt the user to log in and provided the log in was successful, it also prompted the user to consent to allow the client (web application) to access the resource server (API).
If the user consent to, the authorization server will response with the redirect URI, the client send before, adds an authorization code in the query string of that redirect URI and then sends the user’s browser back to the client (web application) to deliver that authorization code, which then is the third HTTP message by using the front channel.
The authorization code is only valid for one use and has to be redeemed within a short period of time, typically under a minute.
So now the client (web application) have that authorization code, which can be used by it to request an access token in order to be able to access the resource server (API).
Therefore the client is now switching to the back channel, to send a secure HTTP Post message directly to the authorization server, including the authorization code, client ID and client secret . In case of using PKCE also the plaintext PKCE secret.
The back channel can be taken for secure because it is a classic client-to-server HTTPS connection.
By using certificates the servers identity can be validated and the connection itself is encrypted and therefore cannot be tampered or modified by someone.
Finally the authorization server validates the request and in case everything looks fine, it responds to the client by using also the back channel with an HTTP Post message including the access token and refresh token and if requested an ID token.
Tokens used in OAuth 2.0 and OpenID Connect
There are primarily 3 types of tokens used in OAuth 2.0 / OIDC:
- Access tokens – tokens that a resource server receives from a client, containing permissions the client has been granted.
- Refresh tokens – used by a client to get new access and ID tokens over time. These are opaque strings, and are only understandable by the authorization server.
- ID tokens – tokens that a client receives from the authorization server, used to sign in a user and get basic information about them.
One further important point good to know about the three different types of token is that the first two ones, the access tokens and refresh tokens, belongs to OAuth 2.0 and are completely opaque to the client. The client itself cannot read or do anything with them and only needs to pass them to the authorization server, which by itself can verify if they valid and granting access to the API dependent on the scopes (permissions) defined in that token.
The ID tokens in contrast belongs to the OpenID Connect extension and can and must be readable by the client, to use the included information (claims), for example to manage access and permissions for this user on the app (client) itself.
Sample of an access token send by the authorization server directly to the client (App).
{
"token_type": "Bearer",
"access_token":"RsT50jbQz0zqLgV3Ia",
"expires_in":3600
"scope":"profile",
"refresh_token":"H4HSMMV2409INW"Bearer Token
A security token with the property that any party in possession of the token (a “bearer”) can use the token in any way that any other party in possession of it can. Using a bearer token does not require a bearer to prove possession of cryptographic key material (proof-of-possession).
Source: https://datatracker.ietf.org/doc/html/rfc6750
Bearer can be simply understood as give access to the bearer of this token. One valid token and no question asked.
Source: https://stackoverflow.com/questions/5925954/what-are-bearer-tokens-and-token-type-in-oauth-2
PKCE
PKCE was originally developed for mobile apps where you have no back channel and secret to transmit the access tokens securely.
As it turns out, the guidance from the OAuth working group is changing to recommend PKCE for all kinds of applications, even if you have a client secret.
By using PKCE in addition with the authorization code flow the following extension is made to this flow.
The Flow by using PKCE starts with the app is creating a random string which is called the PKCE Code Verifier, before the user is redirected to the authorization server, this string is different each time the flow starts. This plaintext code verifier is stored securely in the application itself and is not transmitted to the authorization server.
The application uses this plaintext code verifier and calculates a hash of it called the Code Challenge. As hashing is a one way operation, no one can reverse it back to the plain text code verifier.
This hash the code challenge and the code_challenge_method (used hashing method for example SHA256) is appended by the application as parameter to the redirect URL, pointing to the authorization server. Also the client ID, redirect URL back to the application and scope is appended to this URL.
So the authorization server is now in possession of this code challenge (hash). It will use it when the client wants to exchange the authorization code through the back channel. If the client made the back channel request in order to get an access token, it sends in addition to the authorization code also the plaintext code verifier to the authorization server. As the app is using the back channel, a secure HTTP POST directly from the application to the authorization server, this is not critical.
The authorization server now calculates also the hash by using this plaintext code verifier and the code_challenge_method. After that it compares the hashes and if they match, the authorization server knows that this back channel request comes from the application which original started this flow and therefore wasn’t intercepted by someone else.
Parameter if PKCE is used:
code_verifier -> plain text secret that your app made up at the beginning, you won’t see this code_verifier in the URL of course, it is hashed into the code_challenge which you will see in the URL.
code_challenge -> hash of the code verifier -> A code_verifier is a high-entropy cryptographic random string using the unreserved characters [A-Z] / [a-z] / [0-9] / “-” / “.” / “_” / “~”, with a minimum length of 43 characters and a maximum length of 128 characters.
code_challenge_method=S256 -> the hash method you used S256 for SHA256.
In practice, you may find OAuth servers in the wild that don’t support PKCE for confidential clients yet since that advice is still relatively new. Originally PKCE was invented for the implicit workflow and public clients (mobile apps, native and single-page applications).
S256 (recommended)
Google supports the Proof Key for Code Exchange (PKCE) protocol to make the installed app flow more secure.
The code challenge is the Base64URL (with no padding) encoded SHA256 hash of the code verifier.
code_challenge = BASE64URL-ENCODE(SHA256(ASCII(code_verifier)))
Device Authorization Flow
I also want to describe in short how the Device Authorization Flow works and deviates from the classic Authorization Code Flow.
This Grant or Flow is needed on devices that don’t have a keyboard or event don’t have a browser like Internet of Things devices or smart TVs, any kind of device where a traditional OAuth flow wouldn’t be possible.
The OAuth flow is based on browser redirects where a user can login into the OAuth server and gets redirected back to the application.
So for all devices who needs to access an resource server (API), but don’t include a browser or keyboard to enter a password, the Device Authorization Flow can be used instead.
This flow separates the device that is getting the access token from the device the user uses to log in.
I used this flow already in past when connecting to the Microsoft Graph by using PowerShell and even had no idea that this was the OAuth Device Authorization Flow.
No matter what device it is or even here in my case PowerShell, in all cases when you try to login, like a login button on a TV or other IoT device, you will see on a display a URL and code, you have to browse with a separate device that provides a browser with internet connection like a smartphone or computer and enter that code.
Both devices, the one who requests the access token like here PowerShell, and the device you use to browse to the URL and enter that code, doesn’t need to be connected to each other. The process behind is coordinated through the OAuth server alone.
Behind the scences when the user click on the login button on a device or here in PowerShell entering the Connect-MsGraph Cmdlet
Connect-MgGraph -Scopes “User.Read.All”,”Group.ReadWrite.All”
the device starts the OAuth flow itself.
The device requests a device code and user code by using a HTTP POST to the device endpoint from the authorization server and provides the client_id and scope in the request like:
POST https://authorization-server.com/device
client_id=CLIENT_ID&
scope=profile
The authorization server responds with a new device code and user code, as well as the URL the user should visit to enter the code.
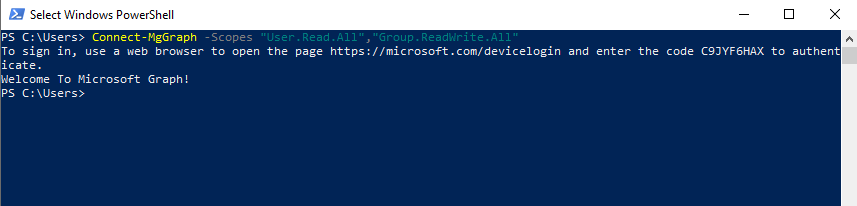
You can capture the traffic behind the connect to the Microsoft Graph API. Here you can see the HTTP response message from the authorization server and device endpoint with the user code, device code, verification_uri and code as mentioned.
Further you can see in the HTTP POST request message from the device (PowerShell here) that the client_id and scope is included.
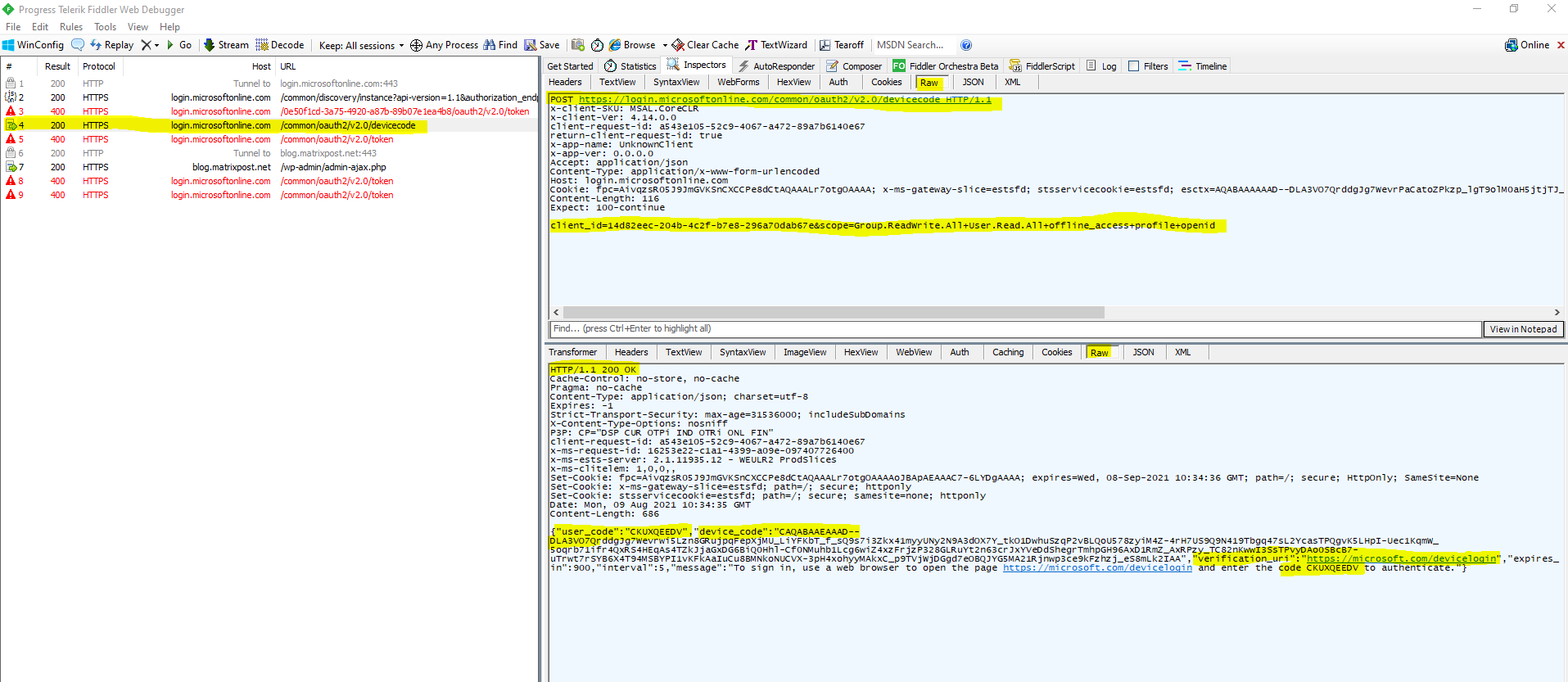
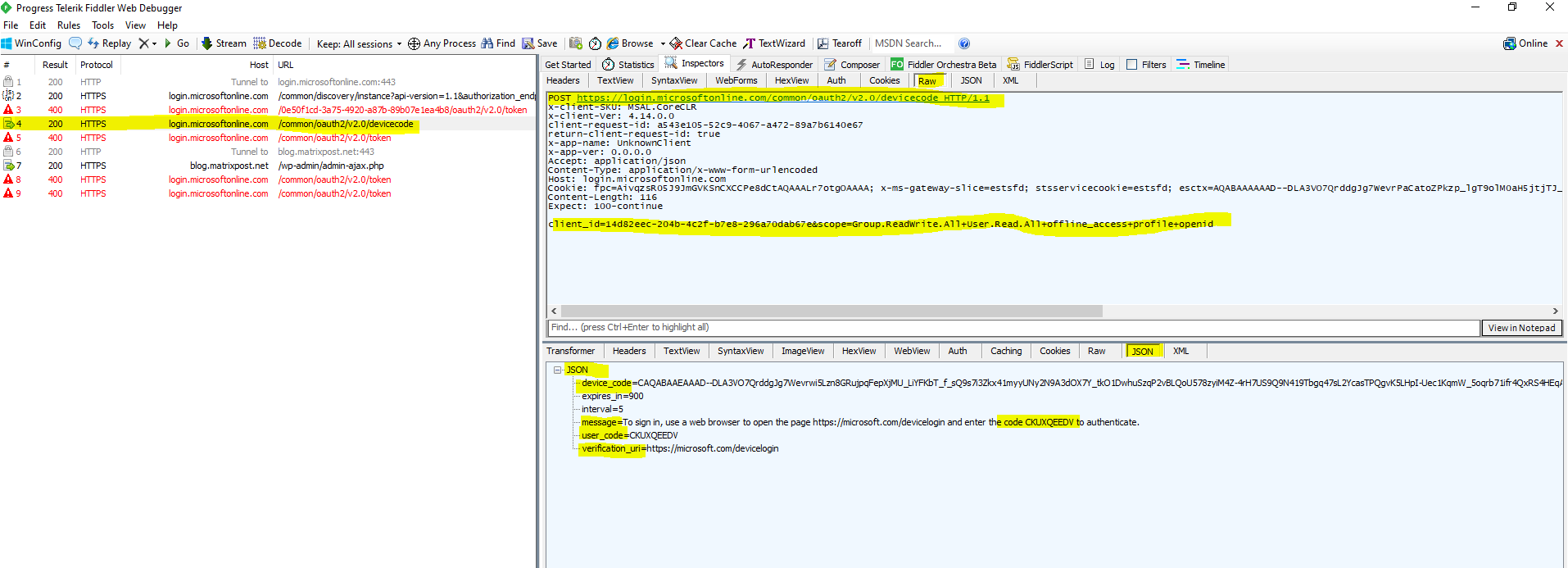
The response will be a JSON document as follows.
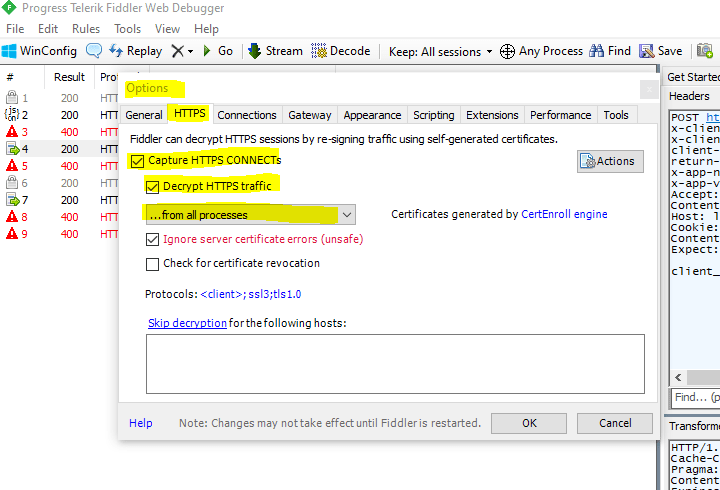
In order to capture not only traffic from browsers only, change this in fiddler into from all processes under tools -> Options to see also the HTTP traffic from PowerShell.
The device code and user code is used by the device to poll the authorization server to see when the user has finished logging into the authorization server.
As you can see above, the JSON response includes also an interval and expires value, the interval tells the device how long it have to wait between the polling requests and the expires value defines how long the data in the response is valid before it expires.
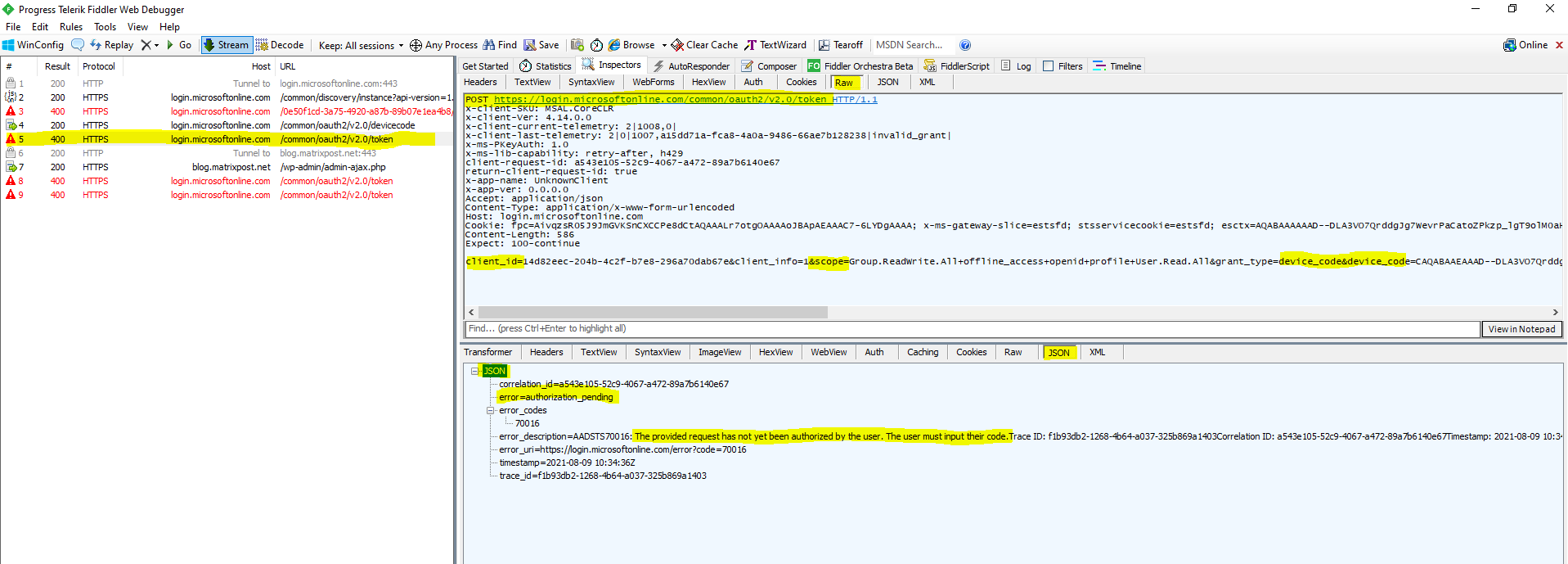
While the device waits for the user to enter the code and authorize the application, the device polls the token endpoint.
You can see one of the polling requests from the device (PowerShell here) and JSON response from the authorization server below.
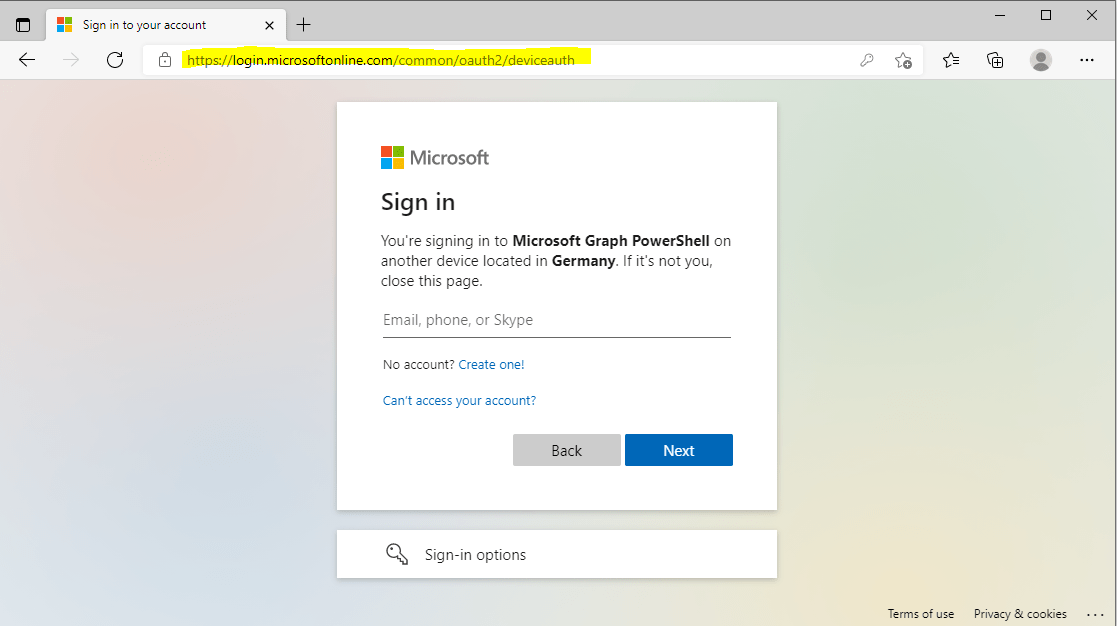
Here the user is logging into the authorization server by using the verification uri and code.
GET https://login.microsoftonline.com/common/oauth2/deviceauth
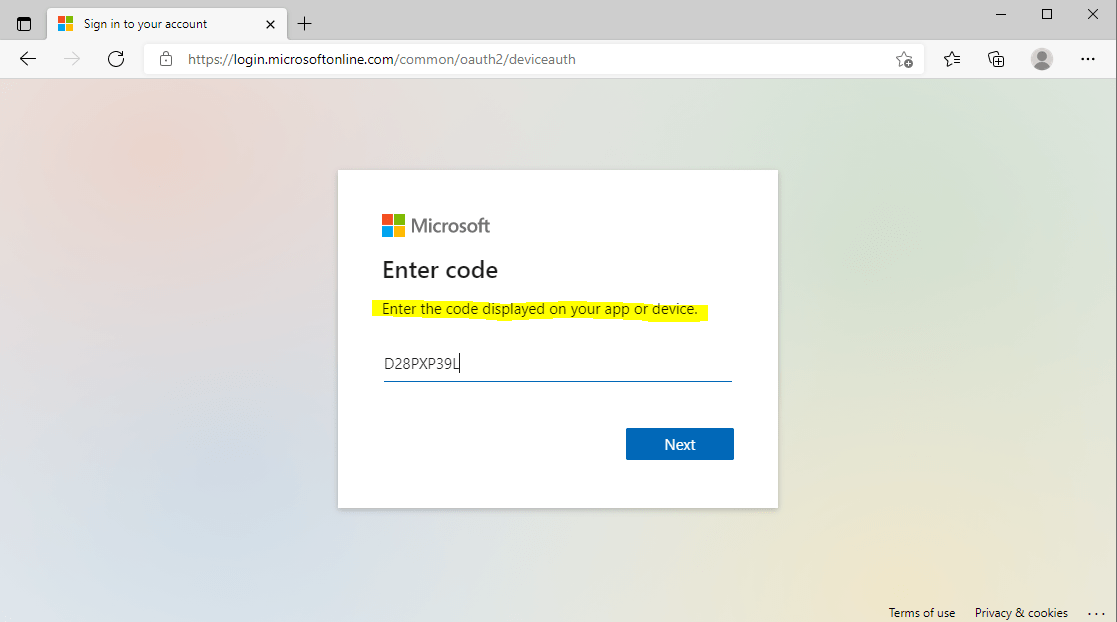
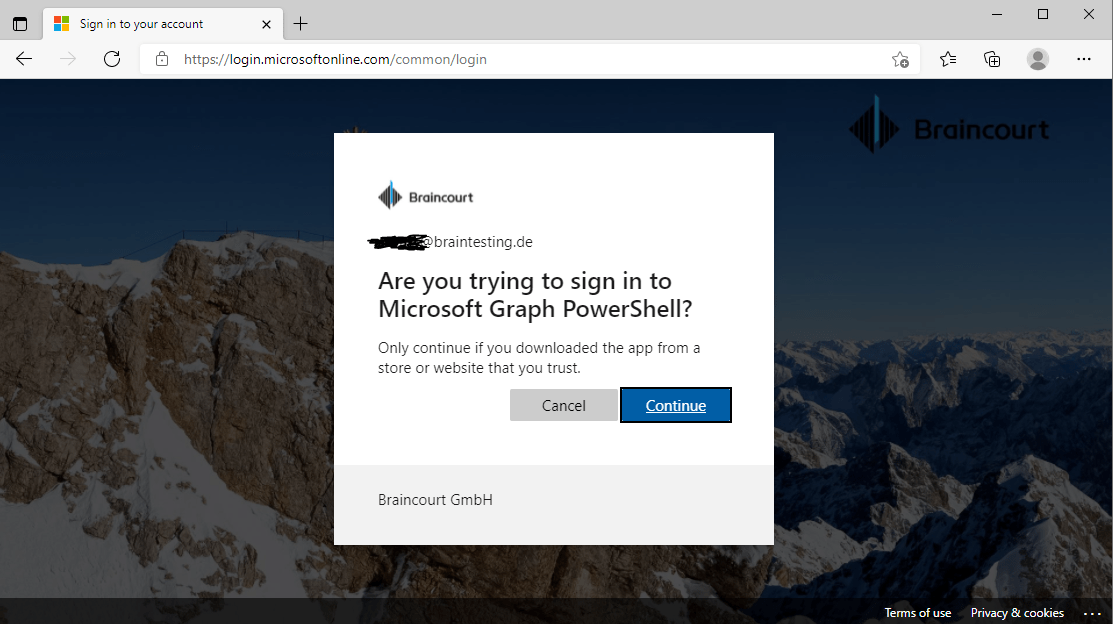
The user will see a prompt that says this device (PowerShell) is trying to access the data resp. resource server.
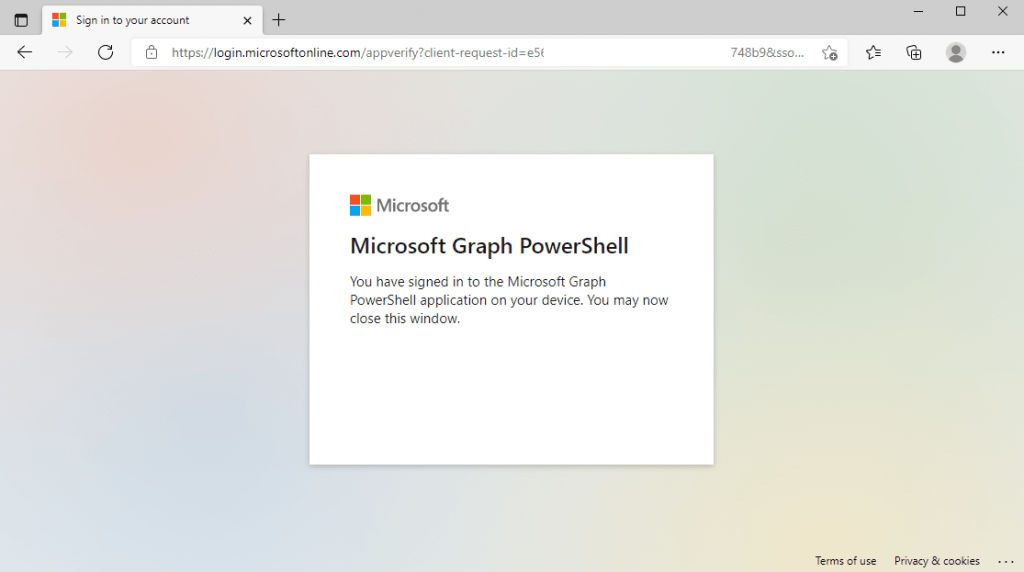
The next time the device makes that polling request by using that long code including the device code, the response will then be the normal OAuth access token response as you can see below in the capture from fiddler.
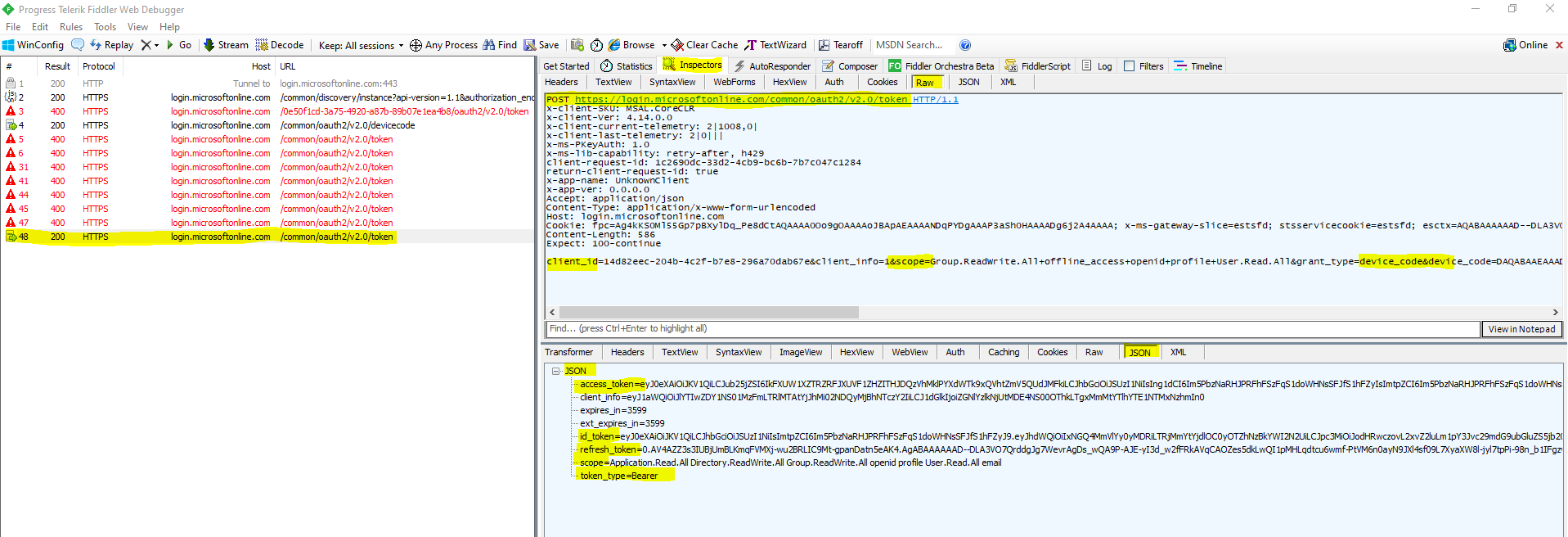
At that point, the device considers the user logged in and can use that access token to make an API request.
To continue to access the resource server (API), the device can use the refresh token instead of going through the process above each time by requesting and bother the user to log in.
History of OAuth
2006 -> Around November 2006, Blaine Cook, chief architect at Twitter, was looking for a better authentication method for the Twitter API, something that didn’t require users giving out their Twitter passwords to third-party apps.
We want something like Flickr Auth / Google AuthSub / Yahoo! BBAuth, but published as an open standard, with common server and client libraries, etc.
– Blaine Cook, April 5, 2007
2007 -> In 2007, a group of people working on the development of OpenID got together and created a mailing list to produce a proposal for a standard for API access control that could be used by any system, regardless of whether it used OpenID.
In the following months, several people from Google and AOL got involved, wanting to support the effort as well. By August 2007, the first draft of the OAuth 1 spec was published, along with several implementations of API clients working against Twitter’s privately-launched prototype of their OAuth API. Eran Hammer joined the project, eventually taking over as community chair and editor of the spec. By the end of the year, the community published 7 updated drafts and the OAuth Core 1.0 spec was declared final at the Internet Identity Workshop.
2009 -> Over the next couple years, work on the OAuth spec moved to an IETF working group, where an effort to publish OAuth 1.1 was started. In November 2009, the editor proposed to drop work on the 1.1 revision and instead focus on a more significantly different 2.0 version. The OAuth 2.0 spec started out as an effort to simplify and clear up many of the aspects of OAuth 1 that were difficult or confusing.
2010 -> OAuth 2.0 rough draft2012 -> OAuth 2.0 was finalized
Source: https://www.oauth.com/oauth2-servers/background/
OAuth 2.0 and OpenID Connect protocols on the Microsoft identity platform
https://docs.microsoft.com/en-us/azure/active-directory/develop/active-directory-v2-protocols
Microsoft identity platform and OpenID Connect protocol
https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-protocols-oidc
OpenID Connect introduces the concept of an ID token, which is a security token that allows the client to verify the identity of the user. The ID token also gets basic profile information about the user.
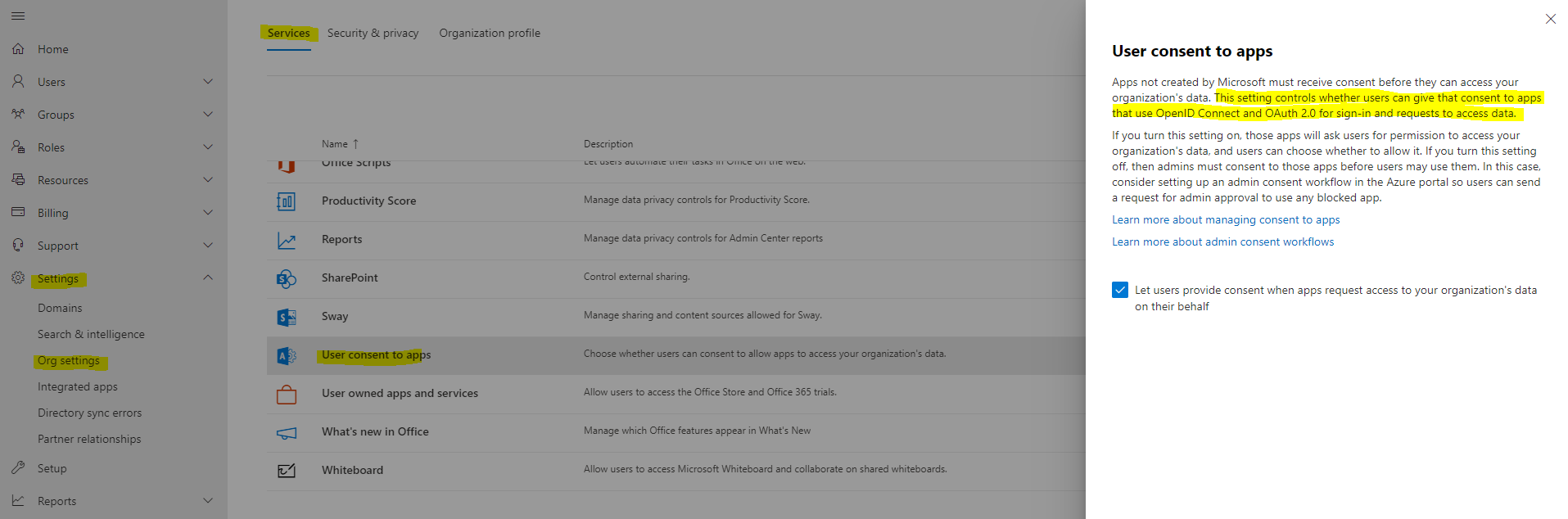
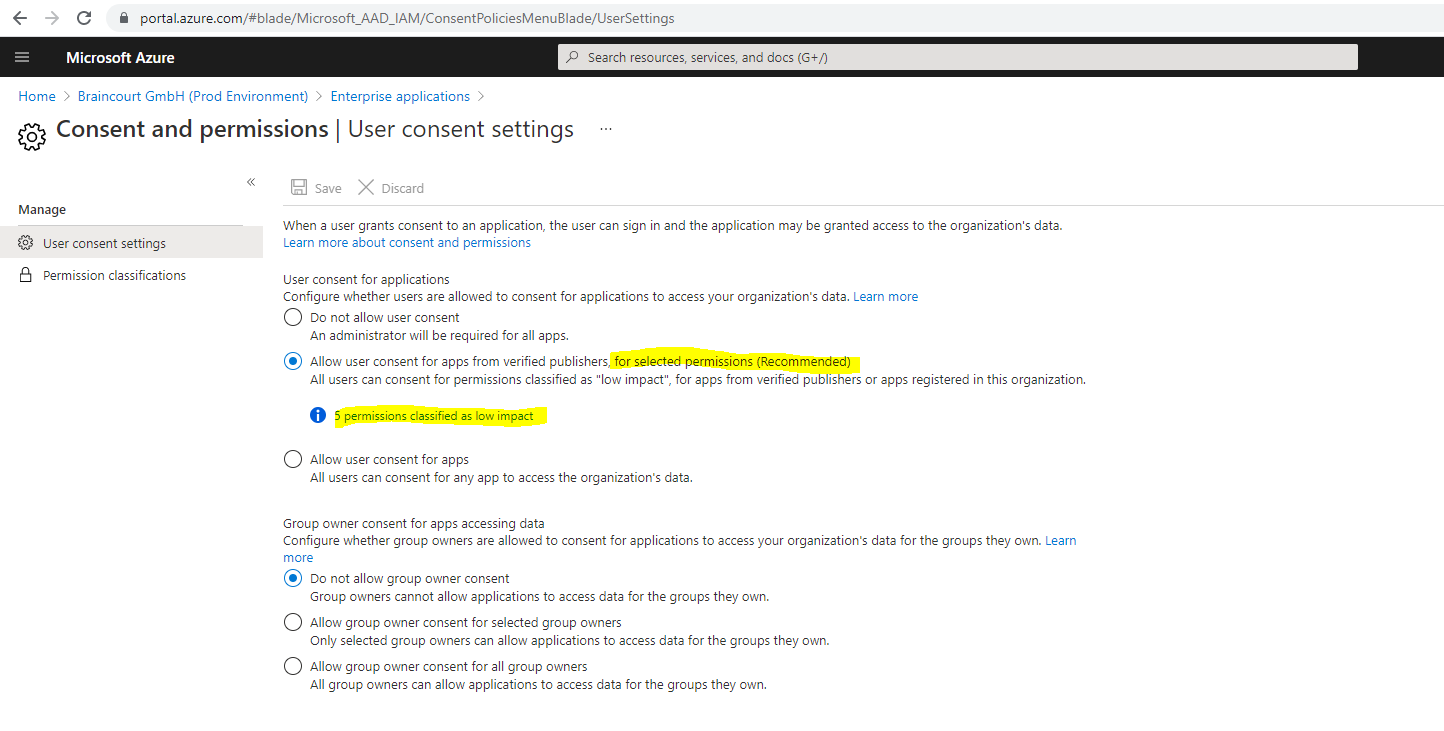
User consent settings in Microsoft 365
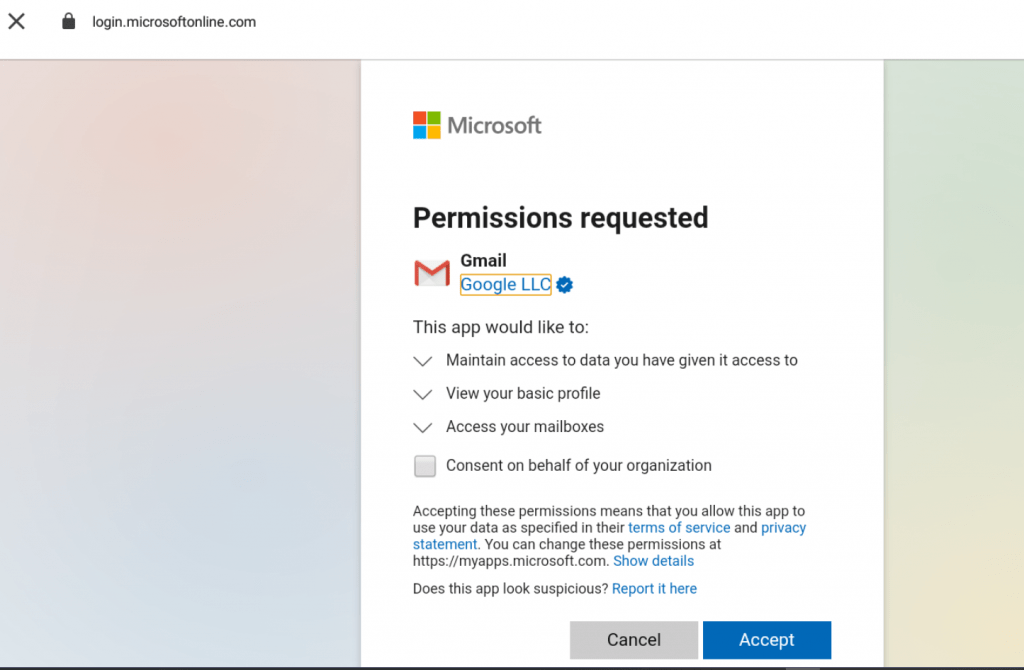
Public 3rd party applications requesting consent in Azure AD.

Links
The OAuth 2.0 Authorization Framework
https://datatracker.ietf.org/doc/html/rfc6749
OAuth 2.0 Simplified
https://www.oauth.com/
https://aaronparecki.com/oauth-2-simplified/
OAuth 2.0 and OpenID Connect (in plain English)
https://youtu.be/996OiexHze0
OpenID Connect FAQ and Q&As
https://openid.net/connect/faq/
Okta Developer Portal
https://developer.okta.com/
Okta website
https://www.okta.com/
Microsoft identity platform and OAuth 2.0 authorization code flow
https://docs.microsoft.com/en-us/azure/active-directory/develop/v2-oauth2-auth-code-flow
OAuth 2.0 and OpenID Connect protocols on the Microsoft identity platform
https://docs.microsoft.com/en-us/azure/active-directory/develop/active-directory-v2-protocols
What the Heck is OAuth?
https://developer.okta.com/blog/2017/06/21/what-the-heck-is-oauth
OAuth and OAuth WRAP: defeating the password anti-pattern
https://arstechnica.com/information-technology/2010/01/oauth-and-oauth-wrap-defeating-the-password-anti-pattern/
Implement the OAuth 2.0 Authorization Code with PKCE Flow
https://developer.okta.com/blog/2019/08/22/okta-authjs-pkce
AD FS OpenID Connect/OAuth Concepts
https://docs.microsoft.com/en-us/windows-server/identity/ad-fs/development/ad-fs-openid-connect-oauth-concepts
Access control for Google Cloud APIs
https://cloud.google.com/docs/authentication?_ga=2.186381865.-1875380339.1624459940
Implicit Flow – Cross-Origin Resource Sharing (CORS)
https://de.wikipedia.org/wiki/Cross-Origin_Resource_Sharing
Azure AD App Registrations, Enterprise Apps and Service Principals (John Savill)
https://www.youtube.com/watch?v=WVNvoiA_ktw