Azure AD Connect Sync Architecture – Simplified
In this post I want take a closer look about Azure AD Connect and how it works exactly under the hood. If you have to troubleshoot sync errors it is important to understand how Azure AD Connect works.
The following article from Microsoft describes very detailed how the Azure Azure AD Connect Sync Architecture works.
Azure AD Connect sync: Understanding the architecture
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/concept-azure-ad-connect-sync-architecture
As mentioned in the title of this post, I want to simplify here the sync architecture of Azure AD Connect.
With Azure AD Connect, you can deploy an Azure Hybrid Cloud where your existing local on-premises network will be extended and connected to Azure.
Azure AD Connect will configure the federation and synchronization from your on-premises Active Directory network with your Azure and Microsoft 365 tenant resp. Azure AD network.
Azure AD is the backbone for authentication in Microsoft 365 (Office 365) and also for other cloud based services like thousands of other SaaS applications.
The predecessors from Azure AD Connect are
- MIIS 2003
- ILM 2007
- FIM 2010
For this post I want to describe the sync architecture for the most common scenario where you connect your on-premises Active Directory with your Azure AD tenant.
Therefore I will use my lab environment braintesting.de
About how to configure and install Azure AD Connect you can read my following post.
After the installation and configuration from Azure AD Connect as shown in the post above, I will first open the Synchronization Service Manager which is installed along with Azure AD Connect.
Here we can see in the Connectors tab the following two connectors
- braintestingde.onmicrosoft.com – AAD (Windows Azure Active Directory) -> Connects Azure AD Connect to Azure AD
- braintesting.de (Active Directory Domain Services) -> Connects Azure AD Connect to on-premise AD
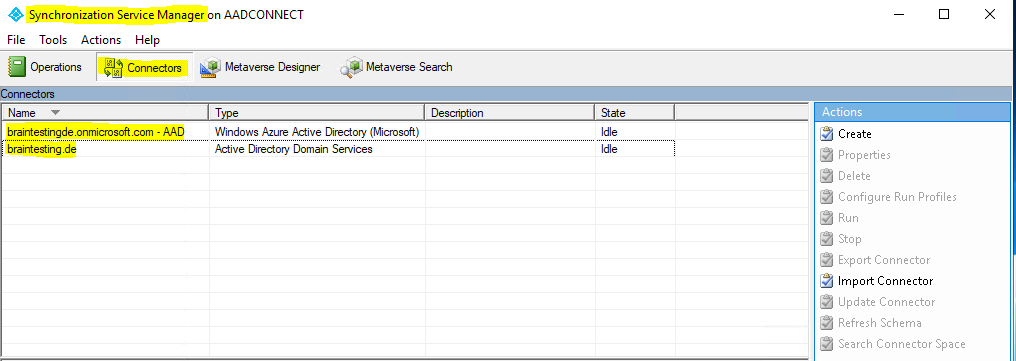
Both connectors are one of the main parts regarding the sync architecture and sync engine. The sync engine is in charge of keeping identity information from predefined objects identical between two or more data sources, in our case between the on-premise Active Directory and Azure AD.
So the sync engine from Azure AD Connect in our case is connected once with our on-premise Active Directory by using the above braintesting.de connector and once with our Azure AD tenant by using the braintestingde.onmicrosoft.com – AAD connector.
Both the on-premise AD and the Azure AD data repositories that are synchronized by the sync engine, are so called connected data sources or connected directories (CD).
The Connector translates a required operation into the format that the connected data source understands. Connectors make API calls to exchange identity information (both read and write) with a connected data source. It is also possible to add a custom Connector using the extensible connectivity framework.
Below in the figure you will see the both data repositories (Active Directory and Azure AD) which are both connected through a Connector to the sync engine from Azure AD Connect.
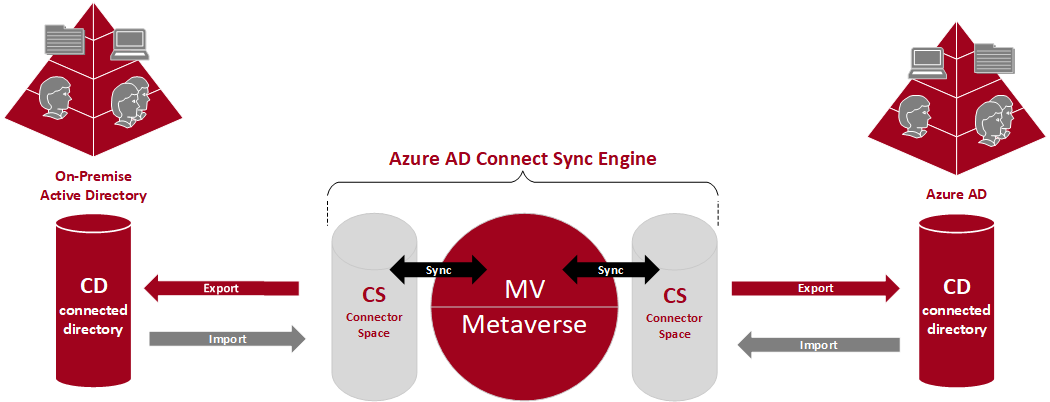
Data can flow in either direction, but it cannot flow in both directions simultaneously. In other words, a Connector can be configured to allow data to flow from the connected data source to sync engine or from sync engine to the connected data source, but only one of those operations can occur at any one time for one object and attribute. The direction can be different for different objects and for different attributes.
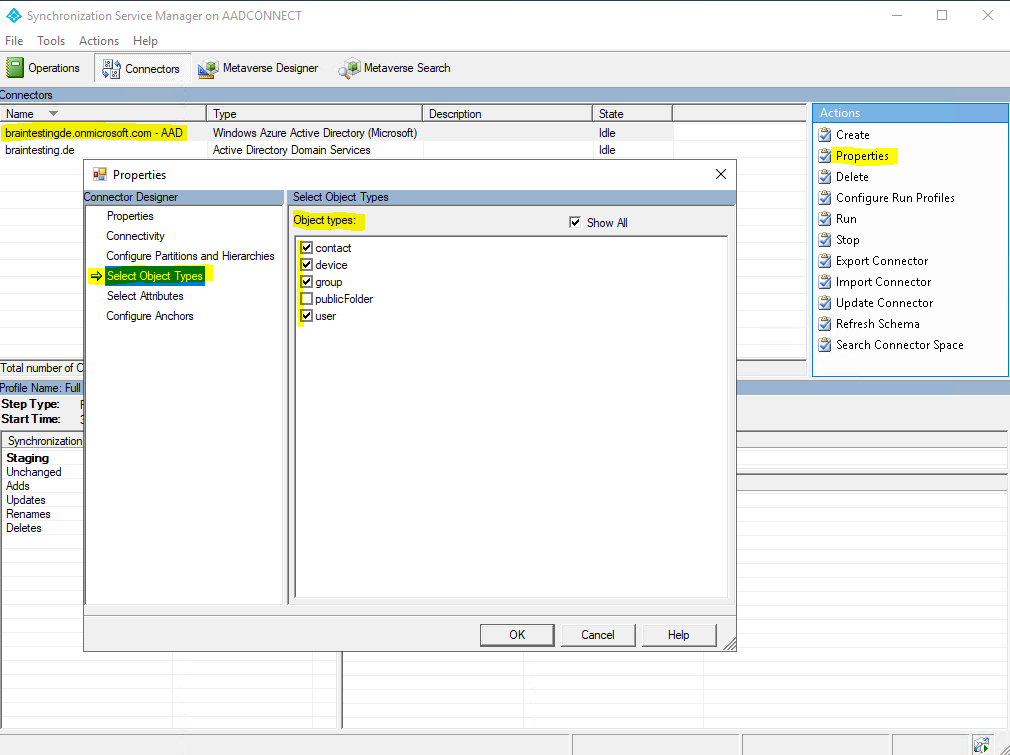
For each Connector you can define what objects from the corresponding data source you want to synchronize with the opposite data source.
Here you can see the objects from the Connector which is connected to Azure AD.
And here the objects from the on-premise Active Directory Connector.
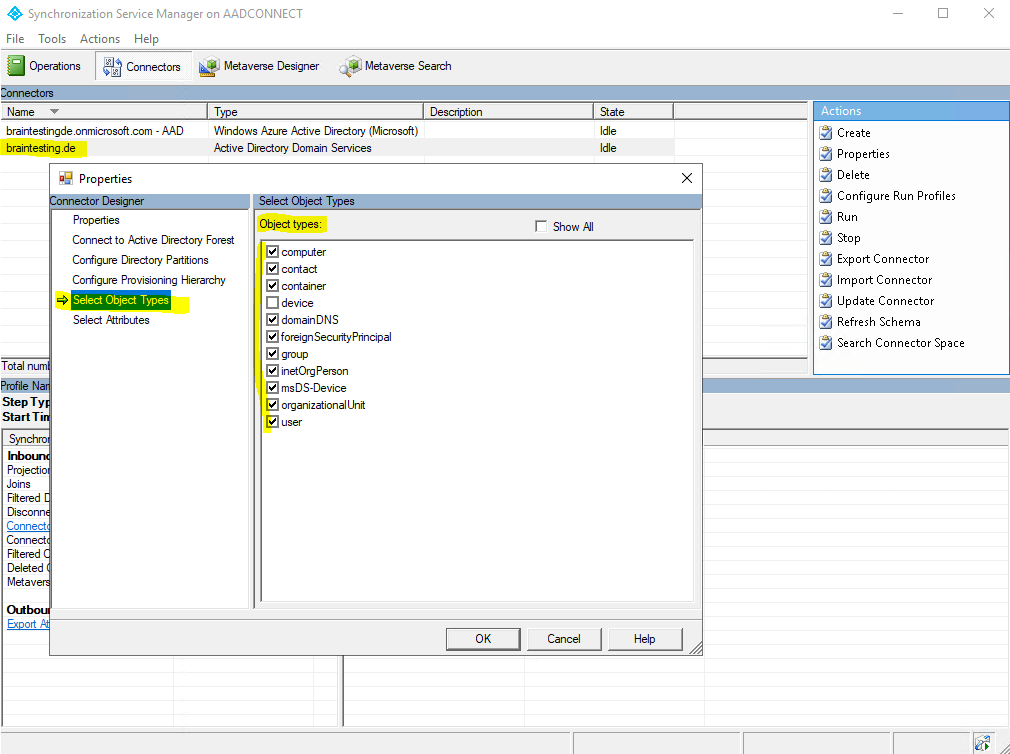
Further each Connector also specifies what attributes from the objects should be synchronized, which is known as an attribute inclusion list.
These settings can be changed any time in response to changes to your business rules. When you use the Azure AD Connect installation wizard, these settings are configured for you.
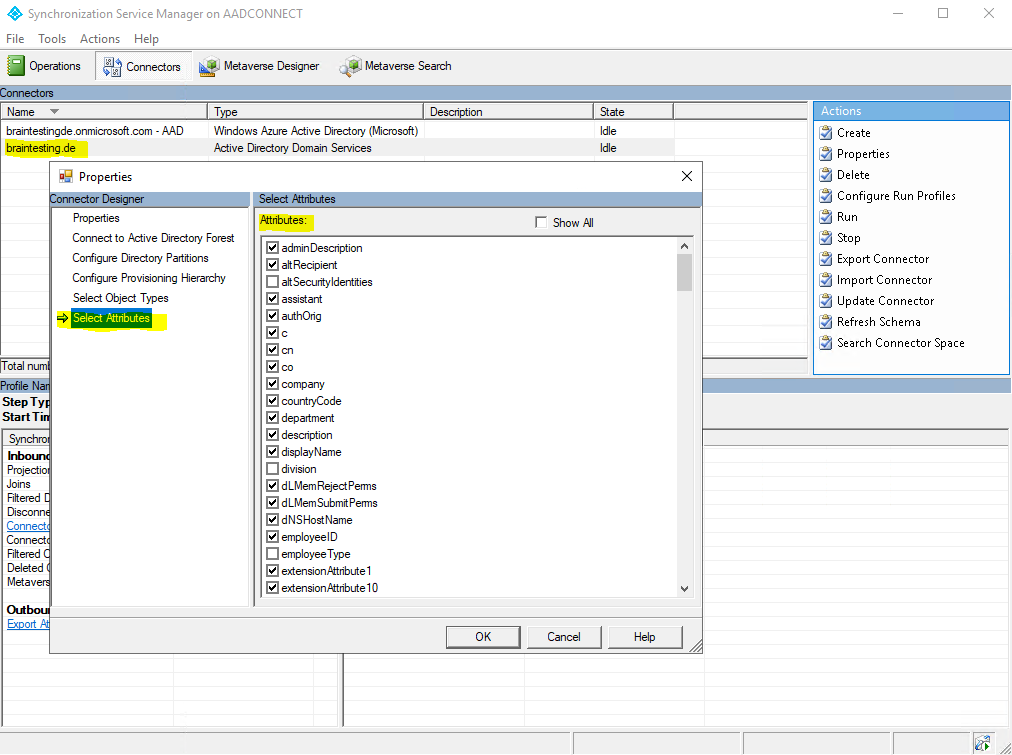
To export objects to a connected data source, the attribute inclusion list must include at least the minimum attributes required to create a specific object type in a connected data source. For example, the sAMAccountName attribute must be included in the attribute inclusion list to export a user object to Active Directory because all user objects in Active Directory must have a sAMAccountName attribute defined. Again, the installation wizard does this configuration for you.
The sync engine from Azure AD Connect is made up of two different data storage, once the connector space (CS) and once the metaverse (MV).
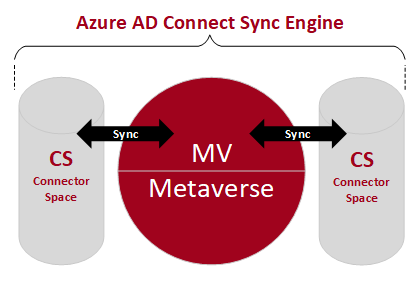
The connector space is a staging area that contains all objects including the attributes we want to synchronize with the opposite data repository (on-premise AD and Azure AD).
The sync engine uses the connector space to determine what has changed in the connected data source and to stage incoming changes. Incoming changes and import means changes from the object in the data source which will be received from the sync engine.
The sync engine also uses the connector space to stage outgoing changes for export to the connected data source. Outgoing changes and export means changes from the object in one connected data source which now have to be updated (exported) in the other connected data source.
So the connector space is a reflection from the data source (origin on-premise or Azure AD) including the changes from the opposite data source.
By using a staging area, the sync engine remains independent of the connected data sources and is not affected by their availability and accessibility. As a result, you can process identity information at any time by using the data in the staging area. The sync engine can request only the changes made inside the connected data source since the last communication session terminated or push out only the changes to identity information that the connected data source has not yet received, which reduces the network traffic between the sync engine and the connected data source.
In addition, sync engine stores status information about all objects that it stages in the connector space. When new data is received, sync engine always evaluates whether the data has already been synchronized.
You can also delete the Connector Space with the Synchronization Service Manager as follows. This will also delete Pending Export objects.
To see pending export objects you need to search the Connector Space by clicking on the desired connector and the link Search Connector Space.

To delete the Connector Space, also select the desired connector and click on Delete.
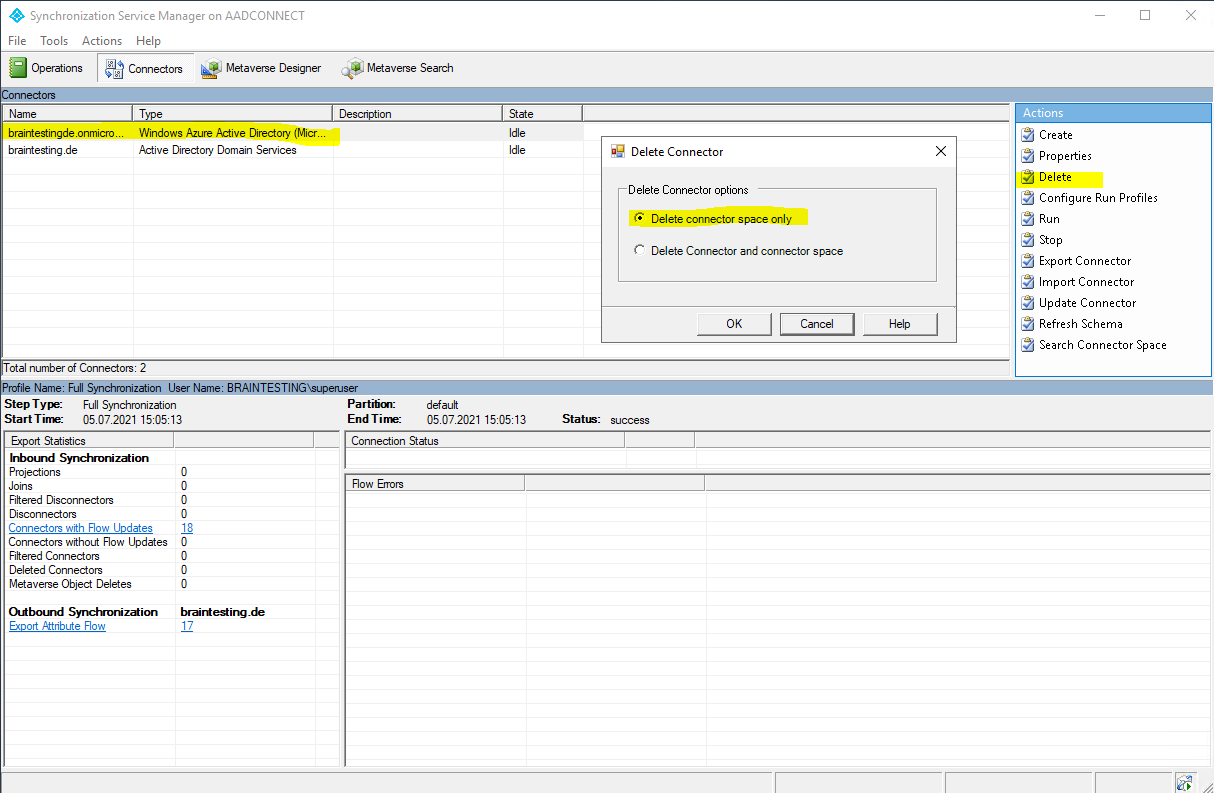
In order to do so, we first need to disable the synchronization.
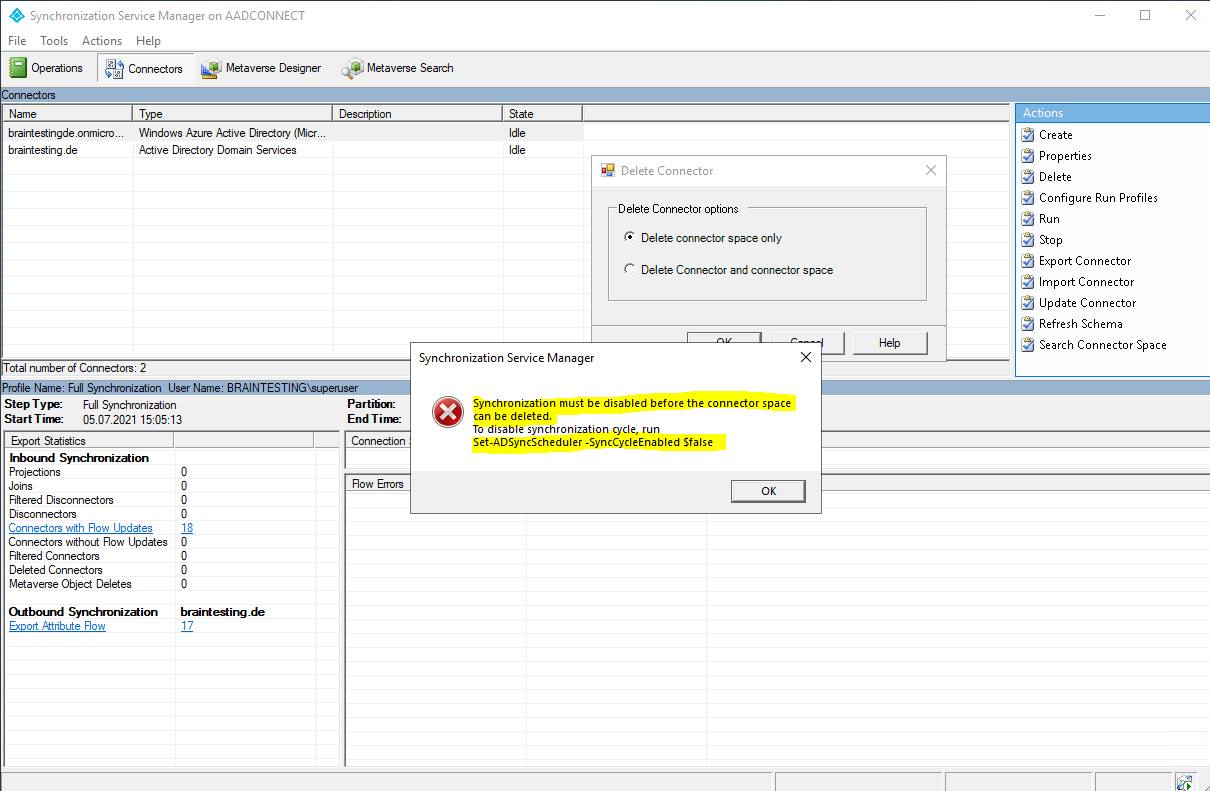
Set-ADSyncScheduler -SyncCycleEnabled $false
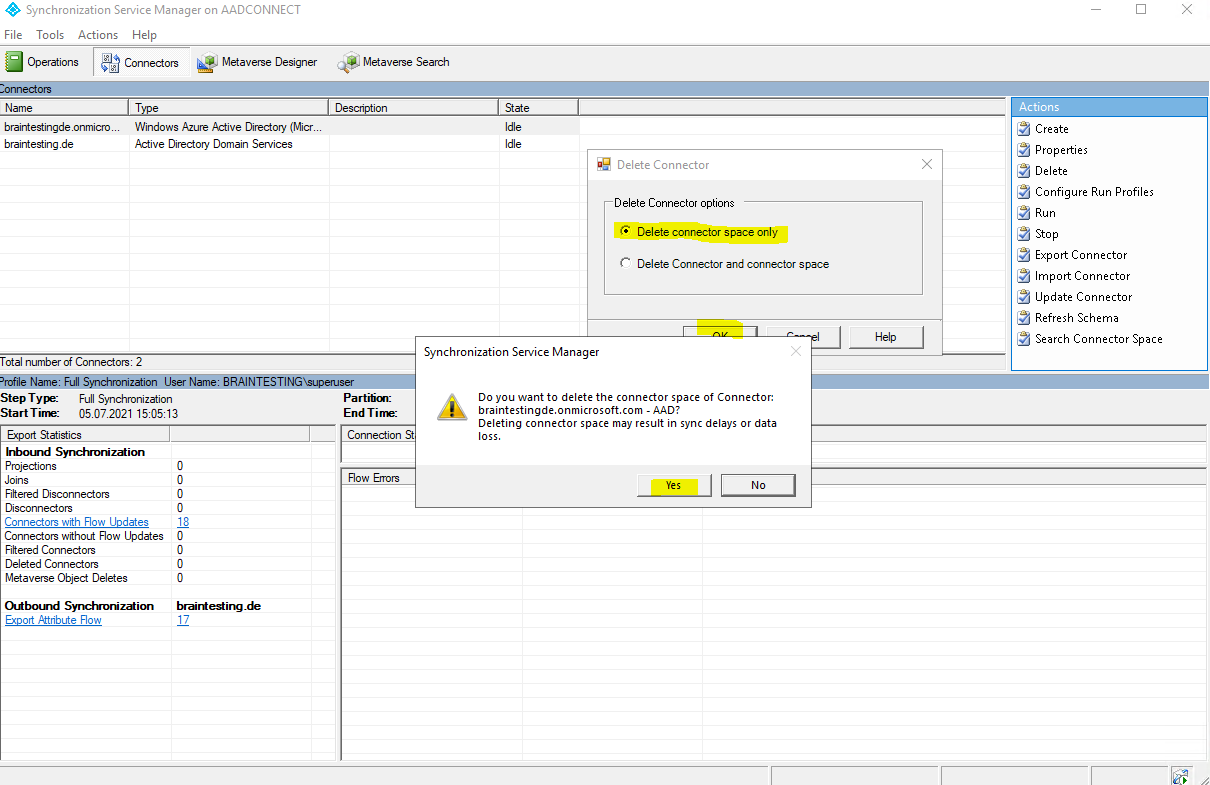
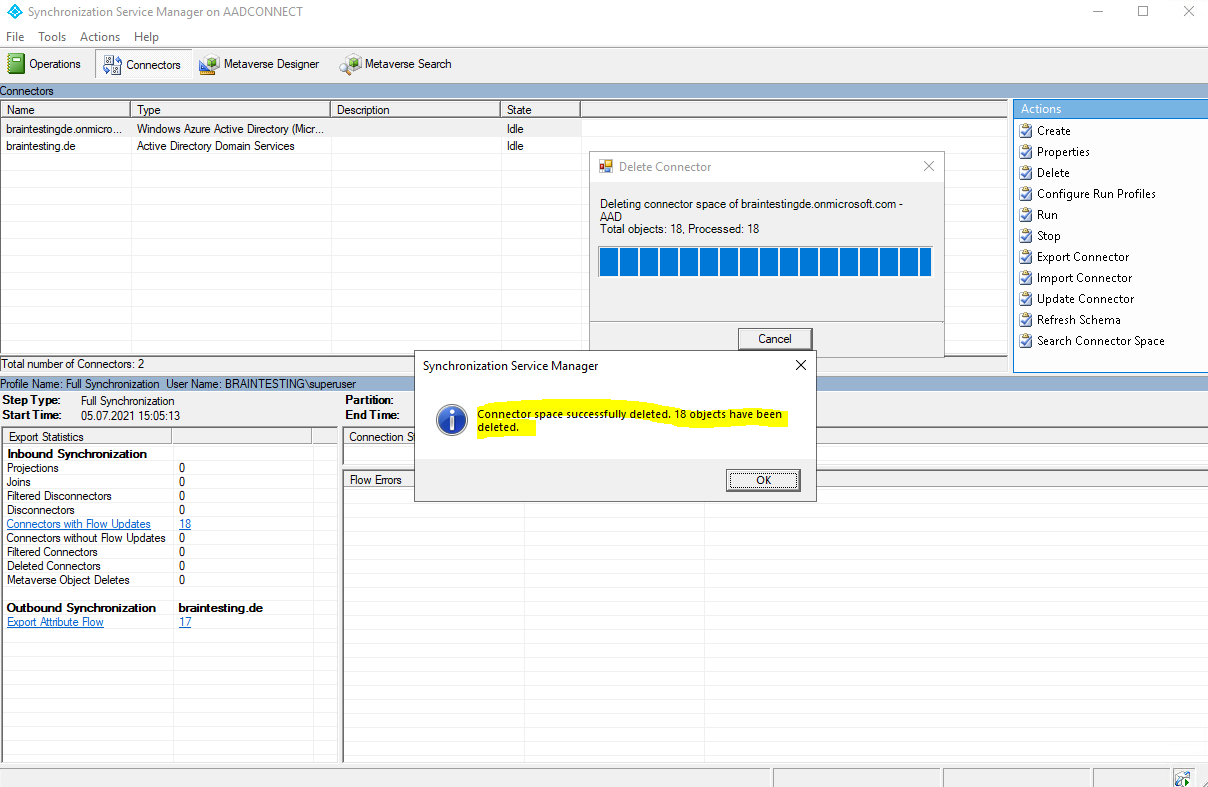
After deleting the Connector Space, we should not forget to enable the synchronization again.
Set-ADSyncScheduler -SyncCycleEnabled $true
The metaverse is a storage area that contains the aggregated identity information from multiple connected data sources, providing a single global, integrated view of all combined objects. Metaverse objects are created based on the identity information that is retrieved from the connected data sources and a set of rules that allow you to customize the synchronization process.
So the metaverse is a storage which stores our object including all changes made to the object from both connected sites (data sources) and in a way the new origin of our object which have to be exported to both sites (data sources).
The export will occur from the connector space, so the object will be first synced between the metaverse and the connector space, and after that, the export from the connector space to the connected data source (directory) will be triggered.
The objects in the sync engine are representations of either objects in the connected data source or the integrated view that sync engine has of those objects.
The integrated view is the object including all changes from both sites.
Every sync engine object must have a globally unique identifier (GUID). GUIDs provide data integrity and express relationships between objects.
When sync engine communicates with a connected data source, it reads the identity information in the connected data source and uses that information to create a representation of the identity object in the connector space. You cannot create or delete these objects individually. However, you can manually delete all objects in a connector space.
All objects in the connector space have two attributes:
- A globally unique identifier (GUID)
- A distinguished name (also known as DN)
If the connected data source assigns a unique attribute to the object, then objects in the connector space can also have an anchor attribute. The anchor attribute uniquely identifies an object in the connected data source. The sync engine uses the anchor to locate the corresponding representation of this object in the connected data source. Sync engine assumes that the anchor of an object never changes over the lifetime of the object.
Many of the Connectors use a known unique identifier to generate an anchor automatically for each object when it is imported. For example, the Active Directory Connector uses the objectGUID attribute for an anchor. For connected data sources that do not provide a clearly defined unique identifier, you can specify anchor generation as part of the Connector configuration.
A connector space object can be one of the following:
- A staging object
- A placeholder
A staging object represents an instance of the designated object types from the connected data source. In addition to the GUID and the distinguished name, a staging object always has a value that indicates the object type.
The sync engine uses a flat namespace to store objects. However, some connected data sources such as Active Directory use a hierarchical namespace. To transform information from a hierarchical namespace into a flat namespace, sync engine uses placeholders to preserve the hierarchy.
Each placeholder represents a component (for example, an organizational unit) of an object’s hierarchical name that has not been imported into sync engine but is required to construct the hierarchical name. They fill gaps created by references in the connected data source to objects that are not staging objects in the connector space.
So finally to simplify the process of keeping both sites and data repositories identical, I want to show the three processes involved in that.
- Import
- Synchronization
- Export
You can see these three processes for each connector under Configure Run Profiles.
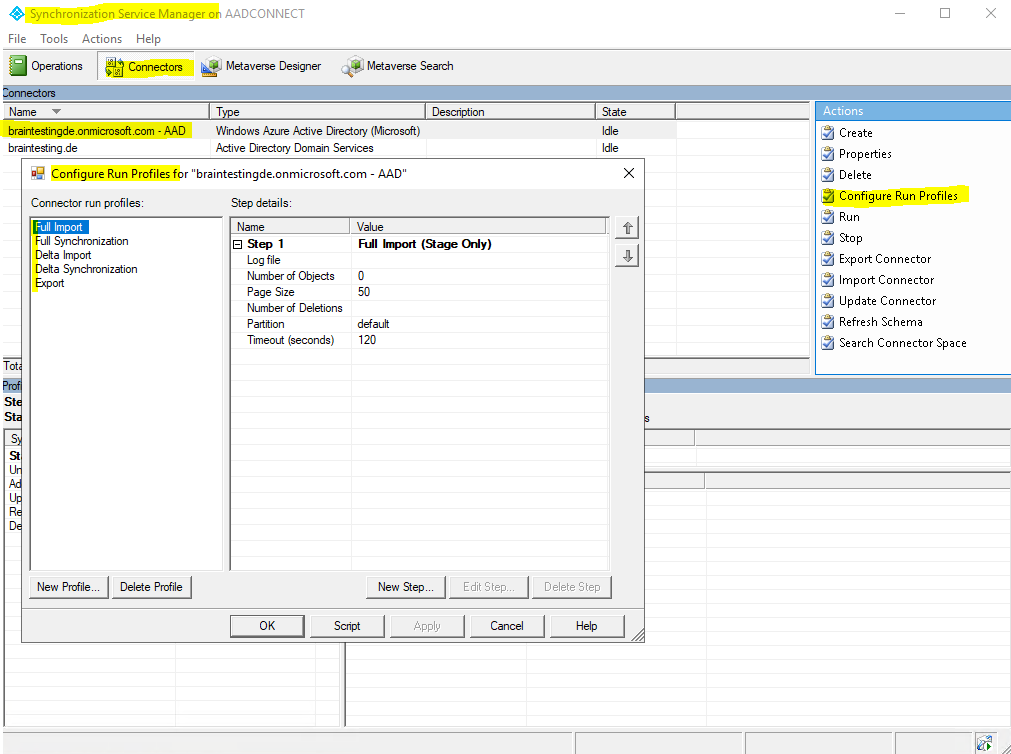
The Synchronization process is between the metaverse and the connector spaces. It will synchronize the object with all updates to the object from both sites between them.
So after the Synchronization between the connector space and the metaverse, the connector space have an updated object which now will be exported from the connector space to the connected data source (CD / directory).
The Import process is between the connected data source (CD /directory) and the connector space. Changes to the object in the connected data source will be imported into the connector space. From the connector space the changes then will be synchronized to the metaverse as mentioned.
These processes are very detailed described in the article from Microsoft as mentioned to the beginning and the following subitem
Relationships between staging objects and metaverse objects
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/concept-azure-ad-connect-sync-architecture#relationships-between-staging-objects-and-metaverse-objects
Btw. I also wanted to mention the Operations tab from the Synchronization Service Manger, which is self-explaining and shows the status of the three processes running in the background.
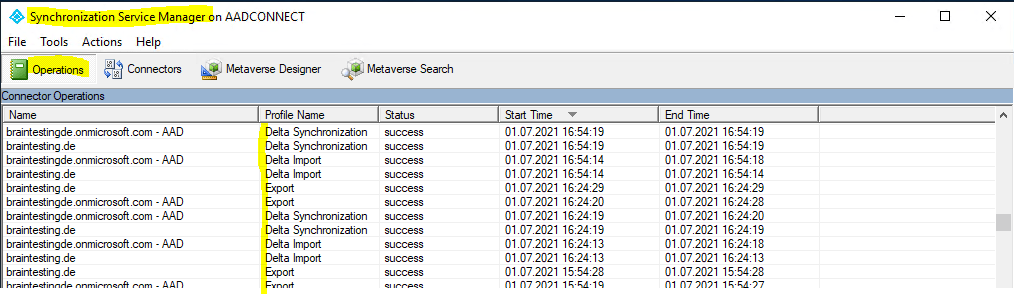
Below you can see again the figure with the data flow from these three different processes.
Azure AD Connect sync: Attributes synchronized to Azure Active Directory
This topic lists the attributes that are synchronized by Azure AD Connect sync. The attributes are grouped by the related Azure AD app.
A common question is what is the list of minimum attributes to synchronize. The default and recommended approach is to keep the default attributes so a full GAL (Global Address List) can be constructed in the cloud and to get all features in Microsoft 365 workloads.
More about at https://docs.microsoft.com/en-us/azure/active-directory/hybrid/reference-connect-sync-attributes-synchronized
Links
Azure AD Connect sync: Understanding the architecture
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/concept-azure-ad-connect-sync-architecture
Azure AD Connect sync: Understanding Declarative Provisioning
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/concept-azure-ad-connect-sync-declarative-provisioning
Control the attribute flow process
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/concept-azure-ad-connect-sync-declarative-provisioning#control-the-attribute-flow-process
Extension attributes for Azure Active Directory
https://docs.microsoft.com/en-us/answers/questions/171019/extension-attributes-for-azure-active-directory.html
Troubleshoot an object that is not synchronizing with Azure Active Directory
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/tshoot-connect-object-not-syncing
Troubleshooting Errors during synchronization
https://docs.microsoft.com/en-us/azure/active-directory/hybrid/tshoot-connect-sync-errors
Understand the Azure AD schema
https://docs.microsoft.com/en-us/azure/active-directory/cloud-sync/concept-attributes