Installing SAP Data Intelligence on Azure Kubernetes Service – Part 1
In this post I want to show how to set up SAP Data Intelligence on Azure Kubernetes Service (AKS).
SAP Data Intelligence is a comprehensive data management solution that connects, discovers, enriches, and orchestrates disjointed data assets into actionable business insights at enterprise scale.
It enables the creation of data warehouses from heterogeneous enterprise data, simplifies the management of IoT data streams, and facilitates scalable machine learning. SAP Data Intelligence allows you to leverage your business applications to become an intelligent enterprise and provides a holistic, unified way to manage, integrate, and process all of your enterprise data.
Source: https://help.sap.com/viewer/835f1e8d0dde4954ba0f451a9d4b5f10/3.1.10/en-US
SAP Data Intelligence Installation Prerequisites
The following infrastructures are required for installing SAP Data Intelligence:
- (Mandatory) A Kubernetes cluster is a prerequisite to install SAP Data Intelligence.
- (Mandatory) A container registry must mirror the SAP Data Intelligence container images and to deploy images created by the Pipeline Engine.
- (recommended): An object store for the purpose of backup/restore, as checkpoint store for SAP Vora.
Configuring SAP Data Intelligence on Cloud Platforms
Configuring SAP Data Intelligence on Azure Kubernetes Service (AKS)
https://help.sap.com/viewer/a8d90a56d61a49718ebcb5f65014bbe7/3.2.3/en-US/11b77bd92743470abe9873cd3010cfb7.html
Source: https://help.sap.com/viewer/a8d90a56d61a49718ebcb5f65014bbe7/3.2.3/en-US/e6c415c802e24847b861cc5a2bd071c4.html
Installing Azure Kubernetes Service
Prepare for Deployment on Azure Kubernetes Service (AKS)
https://help.sap.com/viewer/a8d90a56d61a49718ebcb5f65014bbe7/3.2.3/en-US/b2e335fc36d04a4ab6707818ea284d54.html
I will first create a new resource group where I will place the Kubernetes Service.
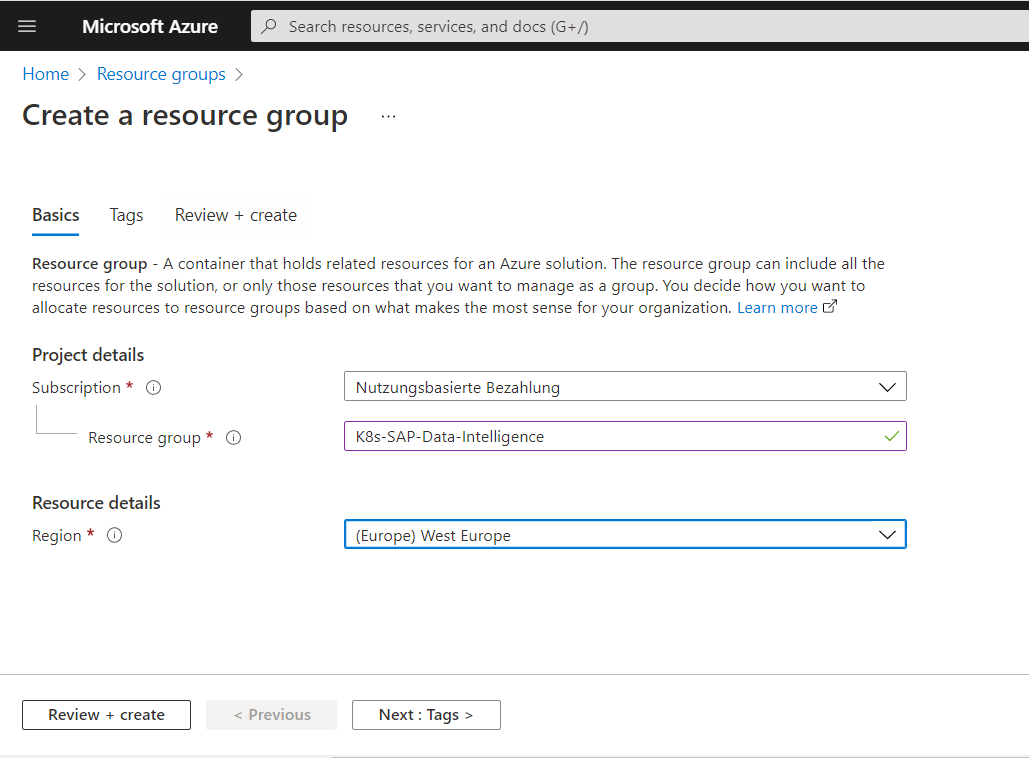
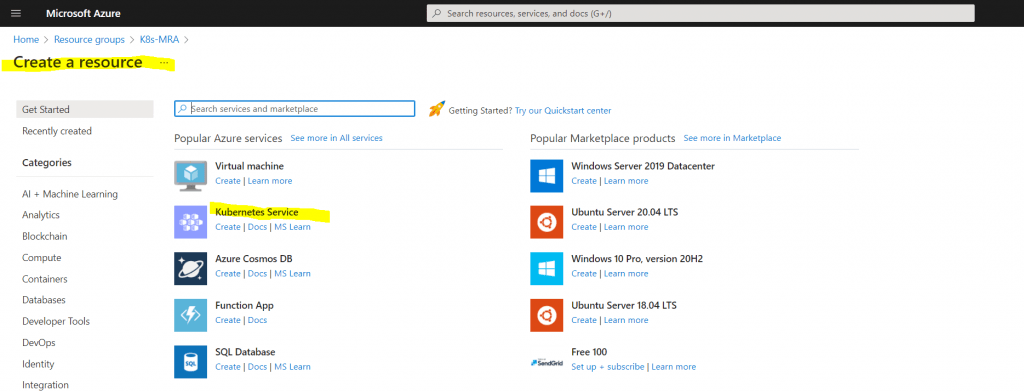
Inside this new resource group we will add the Kubernetes Service.
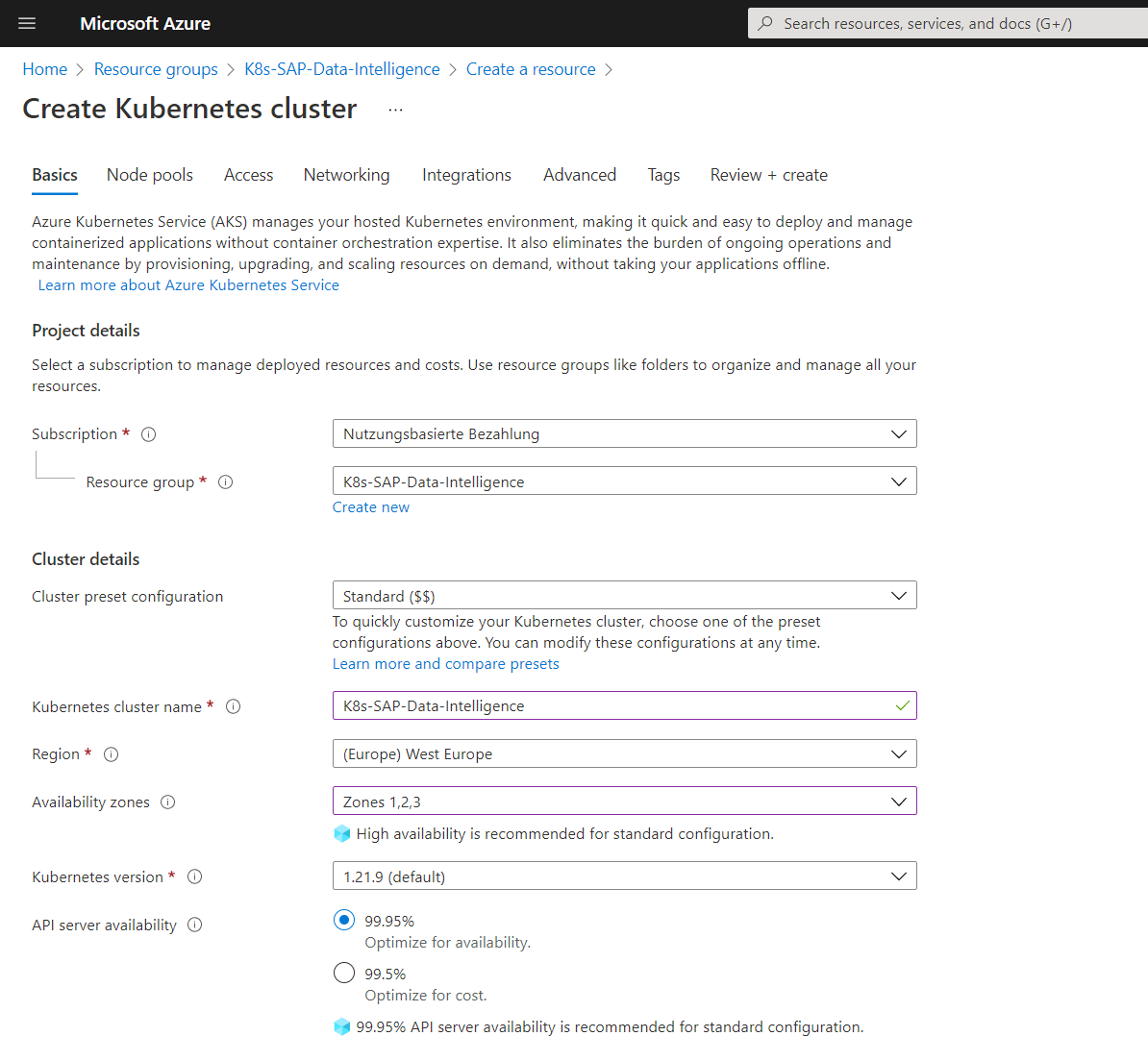
Minimum Sizing for SAP Data Intelligence
For development/test environments, the following minimum sizing is recommended:
- 96 GB RAM, 24 vCPUs, 250 GB disk (persistent volumes)
- 100 GB ephemeral disk for each of the Kubernetes worker nodes (for container images and local storage)
- Container registry with at least 90 GB free space
This configuration allows you to work with around 10 users (on the same tenant) and run up to 10 concurrent pipelines fulfilling the simplicity conditions of section Simplified Sizing Procedure, or a small number of Data Governance jobs (depending on the type, see Sizing for Data Governance). It can be realized with 3 Kubernetes worker nodes, each one having 32 GB RAM and 8 vCPUs. Nodes with less than 32 GB RAM are not recommended.
Sizing Guide for SAP Data Intelligence
https://help.sap.com/viewer/835f1e8d0dde4954ba0f451a9d4b5f10/3.1.10/en-US
Sizing for SAP Data Intelligence 3.1
https://infohub.delltechnologies.com/l/deployment-guide-sap-data-intelligence-on-dell-emc-ready-stack-for-red-hat-openshift-container-platform-4-6-1/sizing-for-sap-data-intelligence-3-1
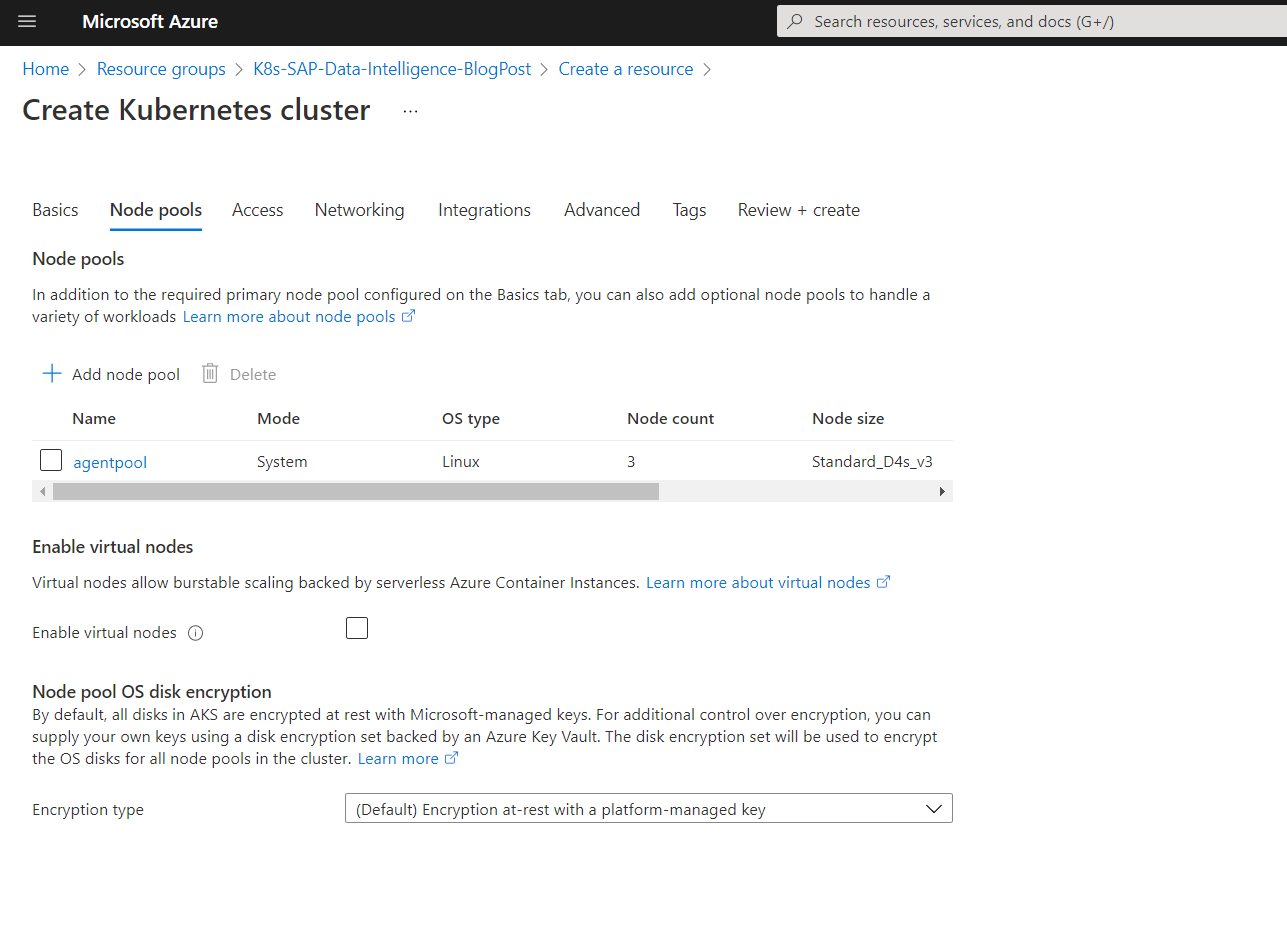
As this setup is only for testing purpose, I will use the following node size in Azure Kubernetes which will also work to show the installation process.
Kubernetes worker nodes, each one having 16 GB RAM and 4 vCPUs
I will use in Azure the node size Standard D4s v3 with the scale method manual and 3 nodes.
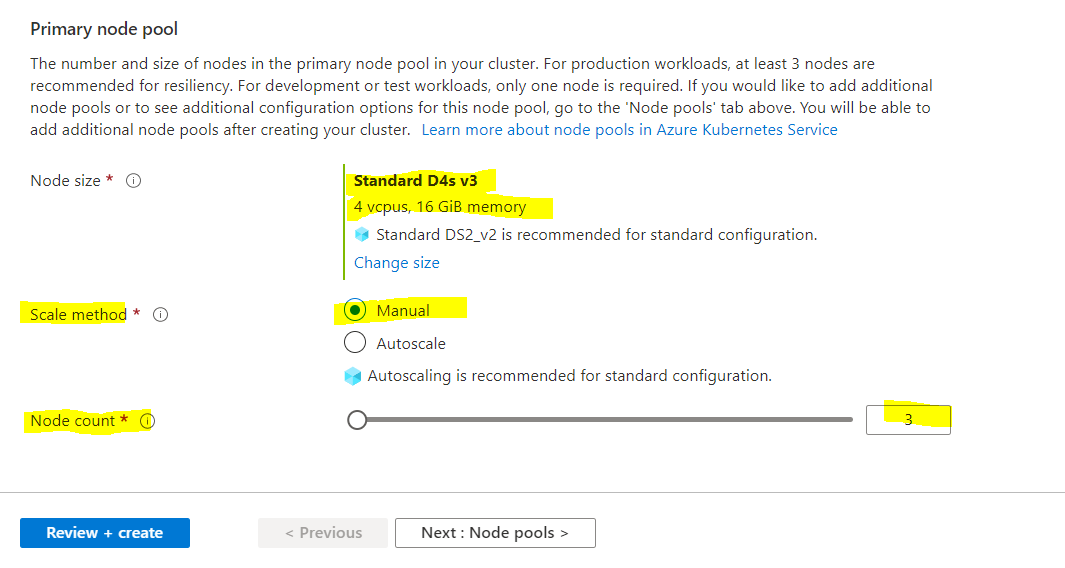
I will user here the default system-assigned managed identity.
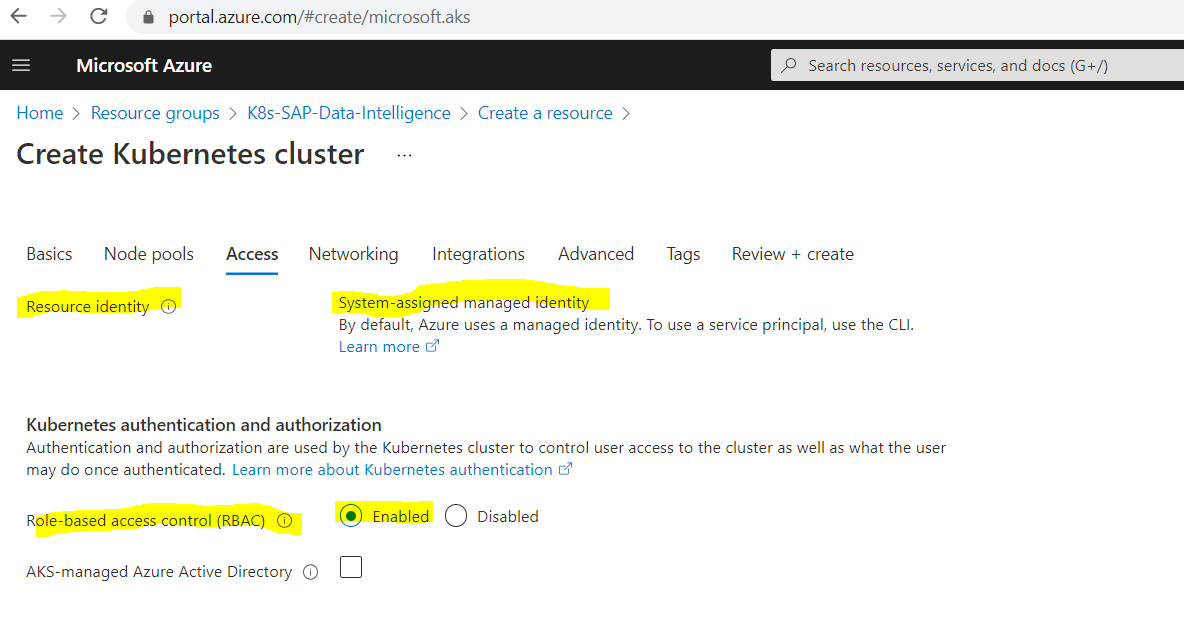
Use managed identities in Azure Kubernetes Service
Currently, an Azure Kubernetes Service (AKS) cluster (specifically, the Kubernetes cloud provider) requires an identity to create additional resources like load balancers and managed disks in Azure. This identity can be either a managed identity or a service principal. If you use a service principal, you must either provide one or AKS creates one on your behalf. If you use managed identity, this will be created for you by AKS automatically. Clusters using service principals eventually reach a state in which the service principal must be renewed to keep the cluster working. Managing service principals adds complexity, which is why it’s easier to use managed identities instead. The same permission requirements apply for both service principals and managed identities.
Managed identities are essentially a wrapper around service principals, and make their management simpler. Credential rotation for MI happens automatically every 46 days according to Azure Active Directory default. AKS uses both system-assigned and user-assigned managed identity types. These identities are currently immutable. To learn more, read about managed identities for Azure resources.
Source: https://docs.microsoft.com/en-us/azure/aks/use-managed-identity
Kubernetes authentication and authorization
Authentication and authorization are used by the Kubernetes cluster to control user access to the cluster as well as what the user may do once authenticated
Source: https://docs.microsoft.com/en-us/azure/aks/managed-aad
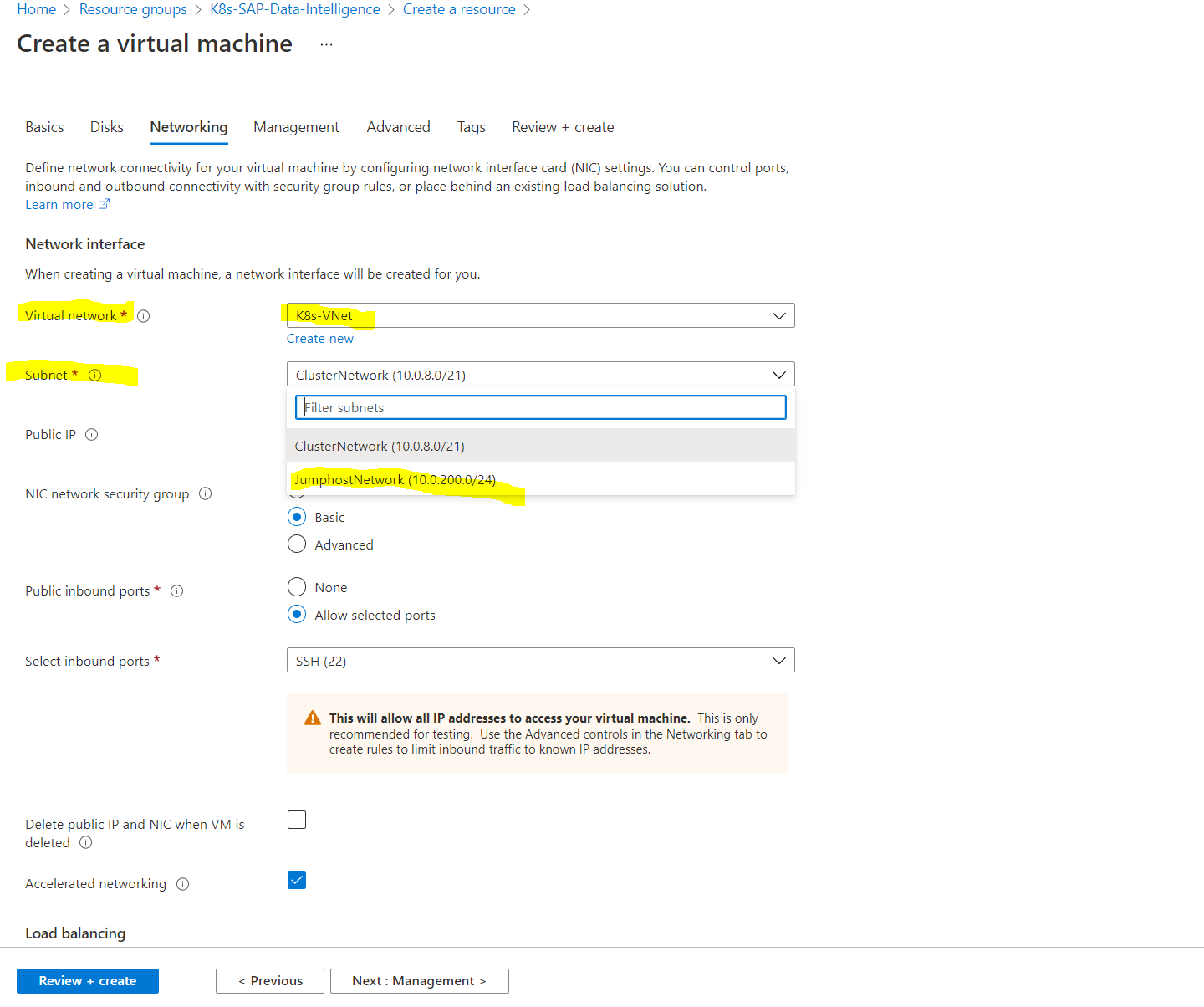
Under Networking I will first create a new VNet which will include a subnet for the kubernetes cluster and one for the jumphost used to configure the cluster.
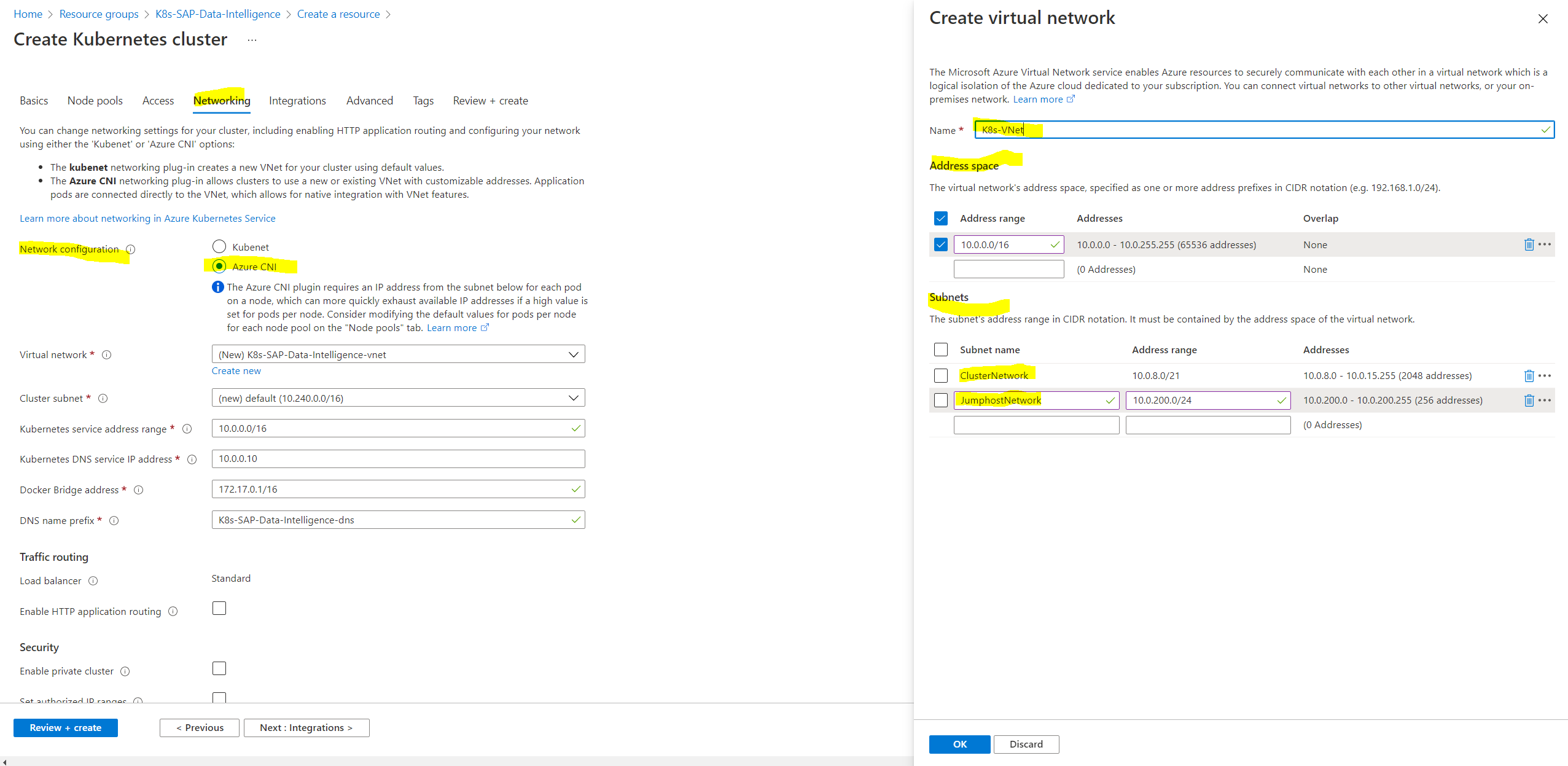
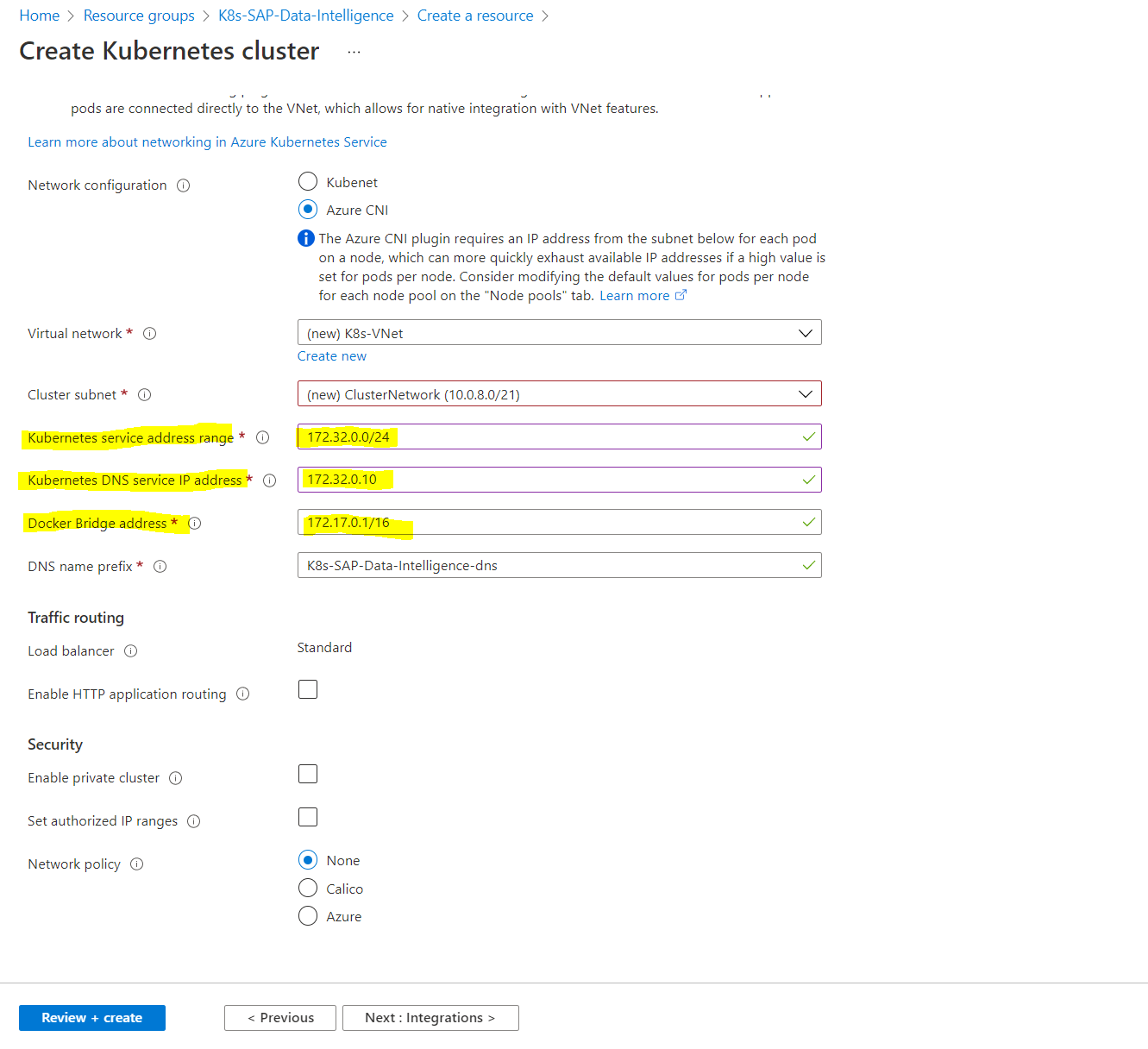
We also need to assign a kubernetes service address range which cannot overlap with any other subnet and our VNet.
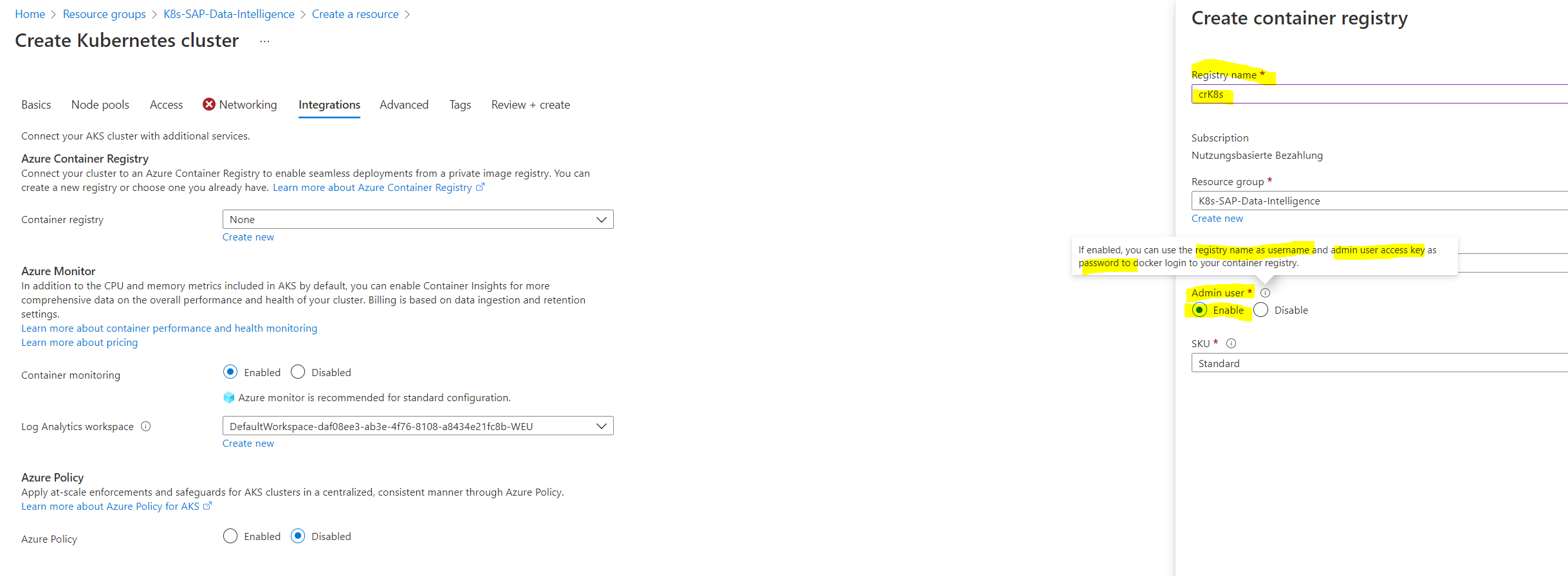
Under integrations we will create a new container registry. To simplify the access from docker, I will enable the Admin user.
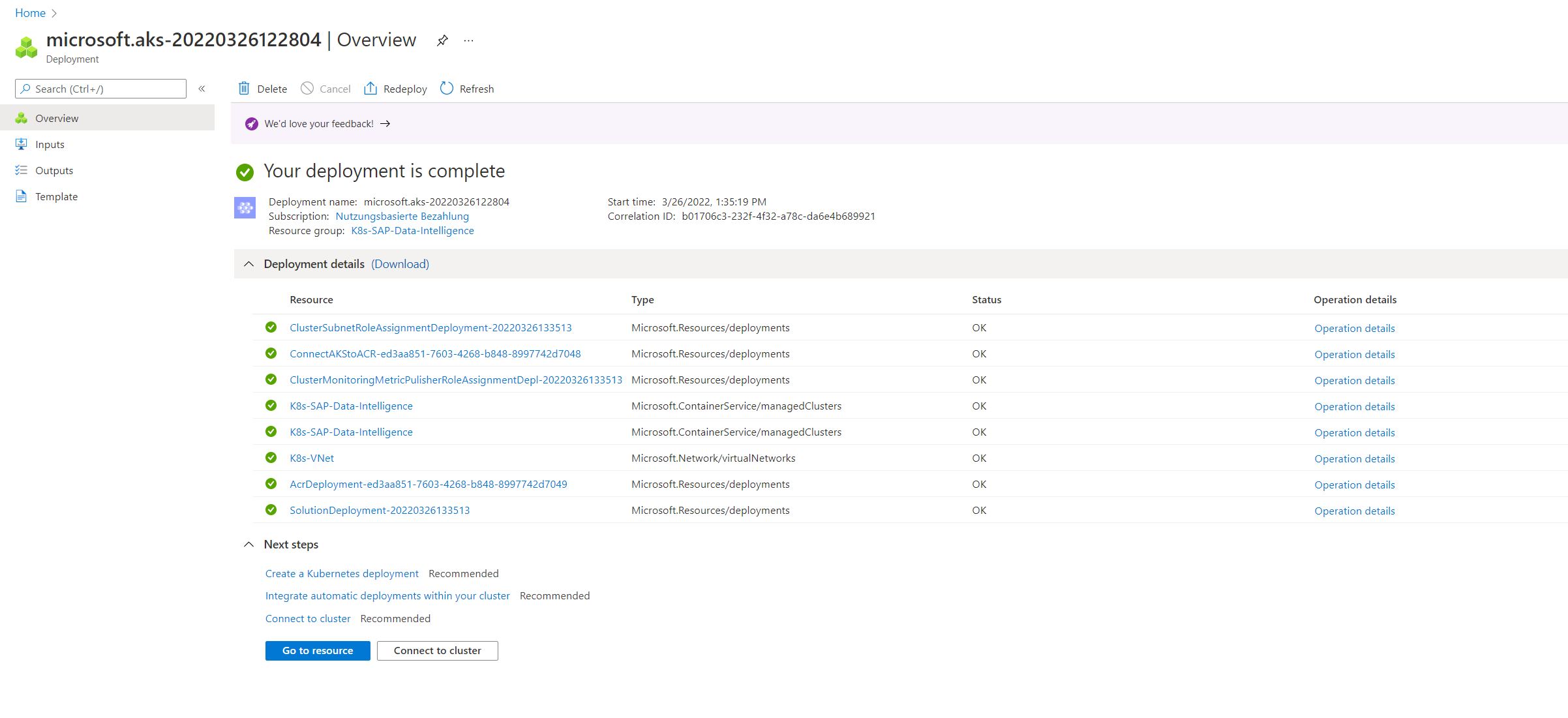
Now I can create the Kubernetes Cluster.

The deployment of the Kubernetes Cluster can take up a few minutes! So grab a coffee ☕ …
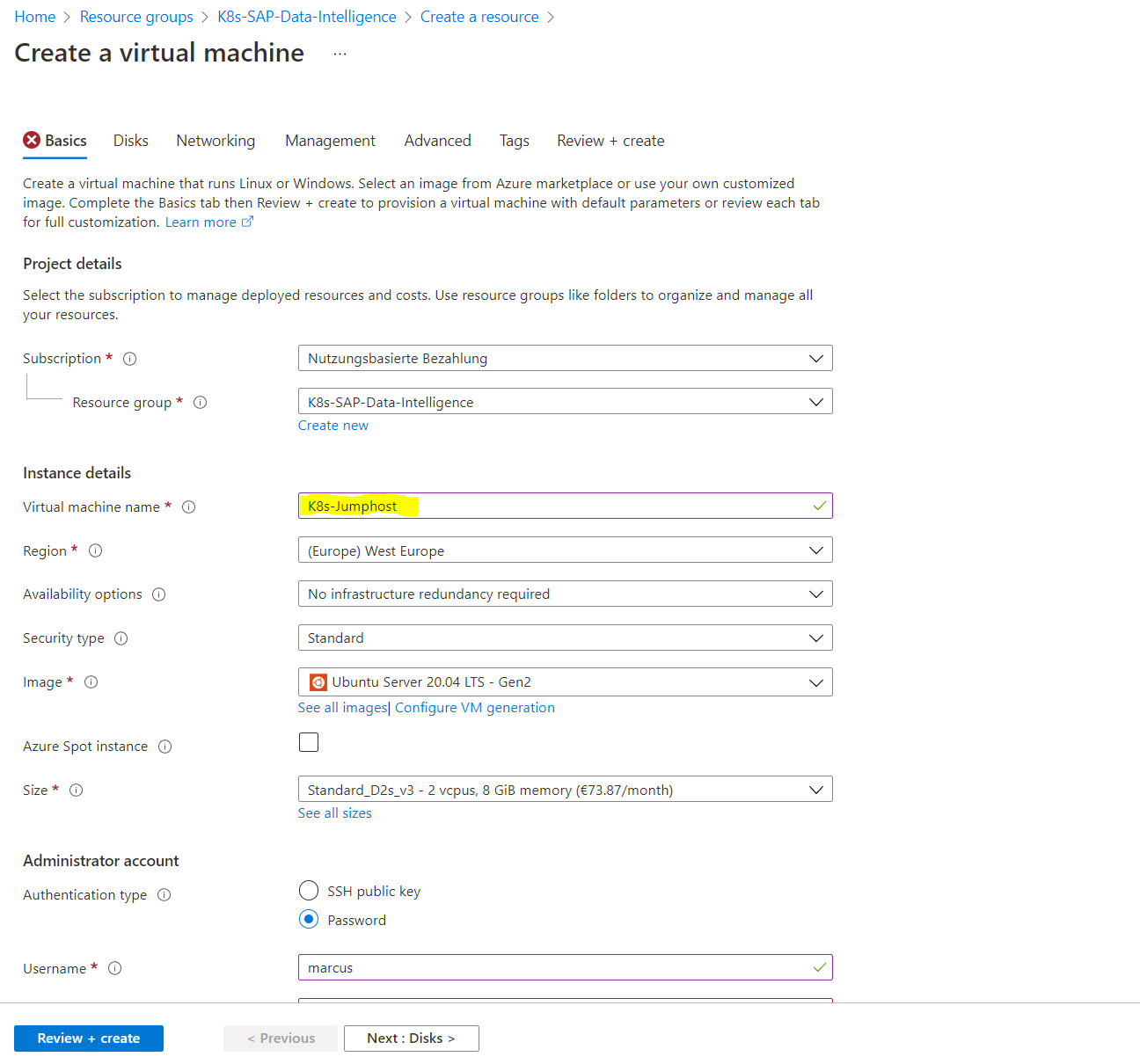
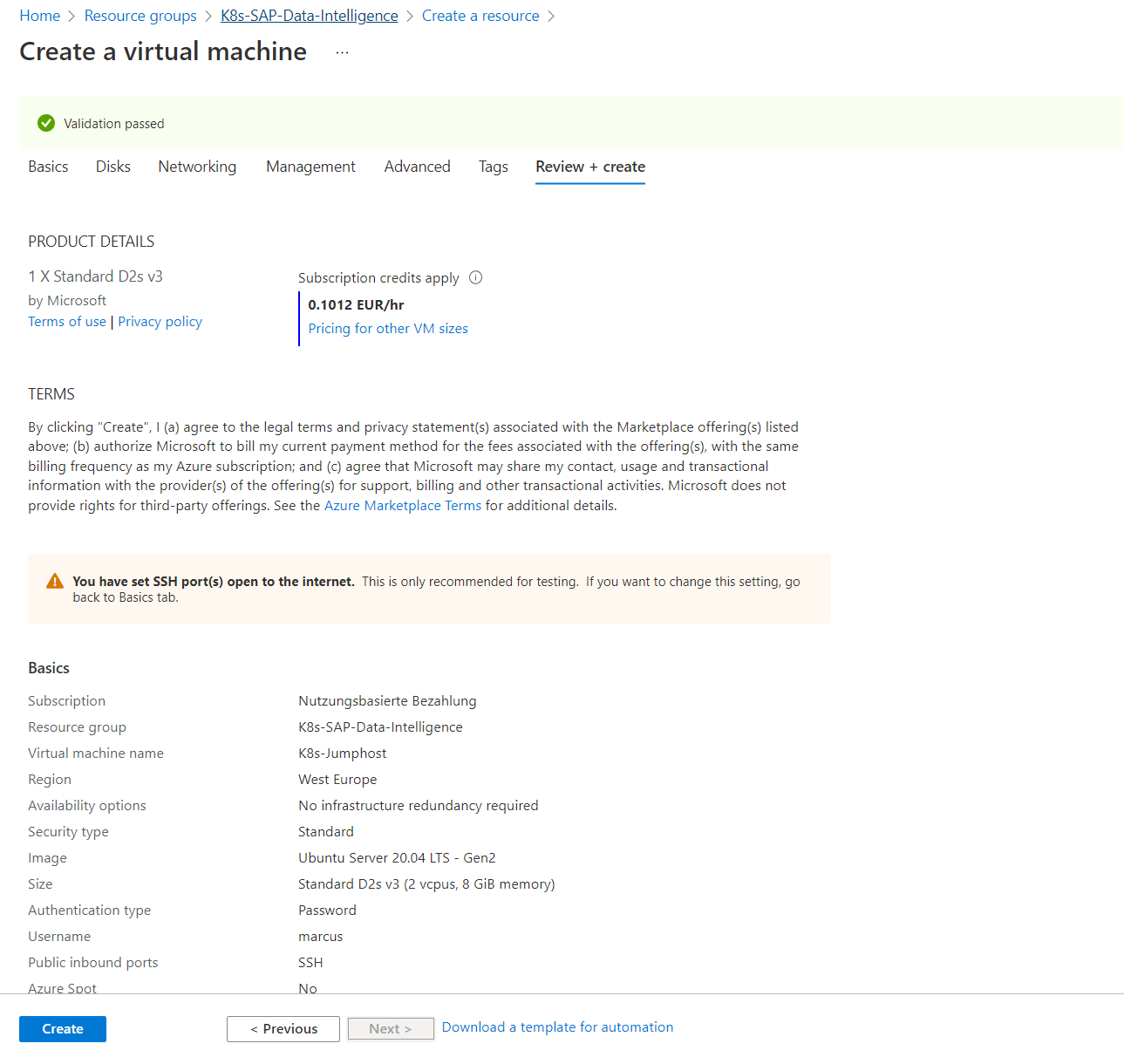
Create a Jumphost to deploy SAP Data Intelligence in the Kubernetes Cluster
Now we can install the jumphost from which we deploy and configure the Kubernetes Cluster and deploy SAP Data Intelligence from.

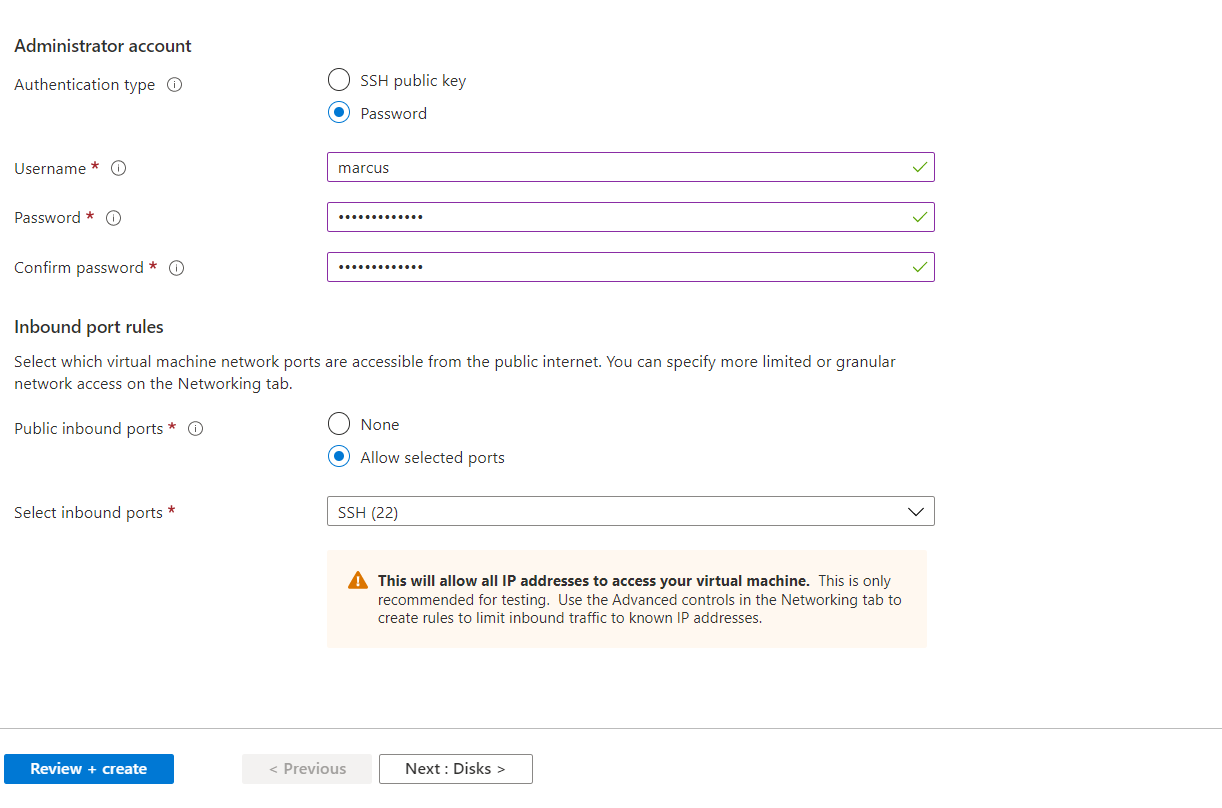
In Part 2 we will first install and configure the tools including the Software Lifecycle Container Bridge 1.0 on the Jumphost in order to deploy SAP Data Intelligence to our Kubernetes Cluster.
Links
Official Installation Guide SAP Data Intelligence 3.2.3
https://help.sap.com/viewer/a8d90a56d61a49718ebcb5f65014bbe7/3.2.3/en-US/c22b0ff1253a4687ba99fe6795d98e89.html
Introduction to Azure Kubernetes Service
https://docs.microsoft.com/en-us/learn/modules/intro-to-azure-kubernetes-service/?WT.mc_id=APC-Kubernetesservices
Quickstart: Create an Azure container registry using the Azure portal
https://docs.microsoft.com/en-us/azure/container-registry/container-registry-get-started-portal
Use the portal to create an Azure AD application and service principal that can access resources
https://docs.microsoft.com/en-us/azure/active-directory/develop/howto-create-service-principal-portal
Azure Container Registry authentication with service principals
https://docs.microsoft.com/en-us/azure/container-registry/container-registry-auth-service-principal
Authenticate with Azure Container Registry from Azure Kubernetes Service
https://docs.microsoft.com/en-us/azure/aks/cluster-container-registry-integration?tabs=azure-cli
How to install the Azure CLI
https://docs.microsoft.com/en-us/cli/azure/install-azure-cli
Install the Azure CLI on Linux
https://docs.microsoft.com/en-us/cli/azure/install-azure-cli-linux?pivots=apt
Sign in with Azure CLI
https://docs.microsoft.com/en-us/cli/azure/authenticate-azure-cli